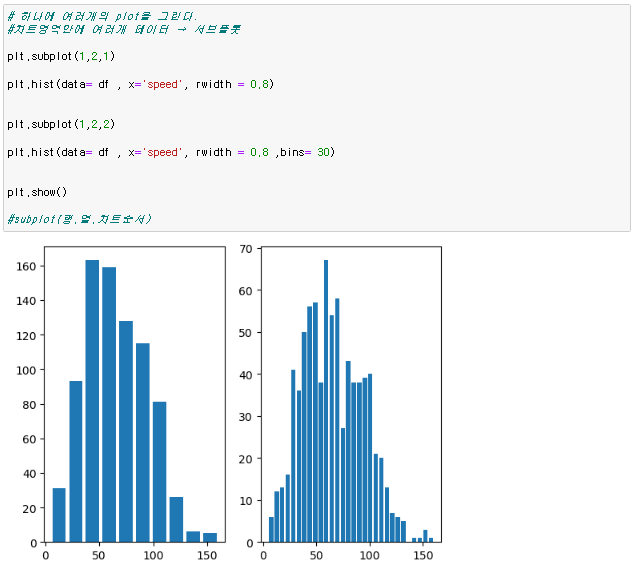
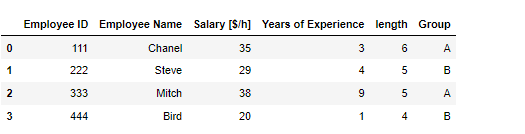파이썬 데이터시각화 라이브러리4 subplots 서브플롯 차트영역안에 여러개 데이터를 표현하는것 plt.subplot(행,열,차트순서번호) 데이터시각화 라이브러리 함수 사용 plt.subplot(행,열,차트순서번호) 데이터시각화 라이브러리 함수 사용 보기 편하게 가로세로 비율 정하기 plt.figure(figsize= (가로,세로) ) 코드 첫번째로 써줌 plt.subplot(행,열,차트순서번호) 데이터시각화 라이브러리 함수 사용 plt.figure(figsize= (가로,세로) ) 파이썬/데이터 시각화 2022.11.28
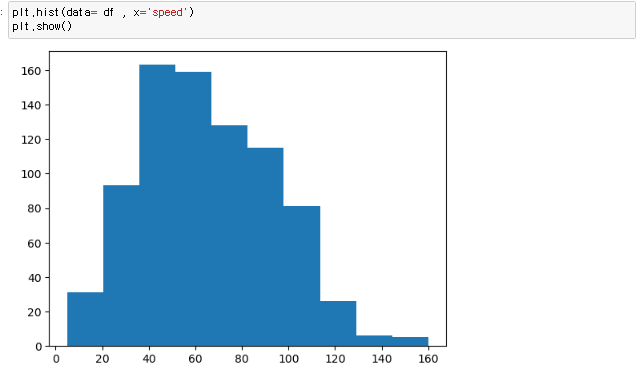
파이썬 데이터시각화 라이브러리3 히스토그램 히스토그램 구간을 설정하여, 해당 구간에 포함되는 데이터가 몇개인지 세는 차트 각 구간을 bin이라고 하며 보통 복수형인 bins라고 부른다 히스토그램은 똑같은 데이터를 가지고 bin에따라 차트모양이 바뀌기 때문에 해석이 달라진다 plt.hist(data= 데이터프레임 , x='컬럼') 직관성이 떨어지니 막대 사이 간격을 조정하는 파라미터는 rwidth = 0.n n의 간격 bins = n n은 디폴트가 10개이고 수정가능 모든 범위에서 빈값을 나눌경우 최소값과 최대값으로 범위를 지정해서 변수로 지정해서 bins에 넣어저도 가능하다 히스토그램 기본 plt.hist(data= 데이터프레임 , x='컬럼명', rwidth = 0.n, bins = ) 파이썬/데이터 시각화 2022.11.28
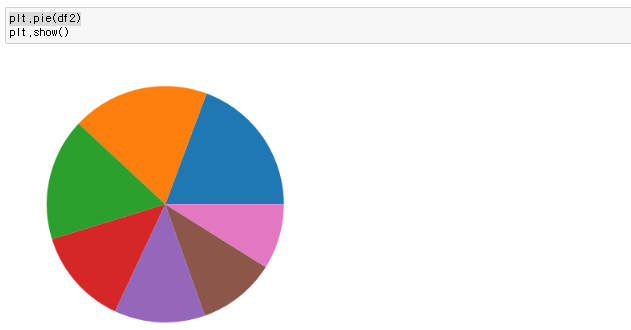
데이터시각화 라이브러리2 파이차트 파이차트 데이터를 퍼센테이지로 비교해서 보고싶을때 사용하며 특정컬럼을 불러와서 표현하면됨 plt.pie(변수, labels= '컬럼변수'.index) 파라미터 autopct='%.nf 파라미터의 autopct 는 %.nf 소수점 n번째 자리까지 표현 startangle = 파이차트 시작 각도 wedgeprops={'width' : 0.n} ) n은 구멍 크기 plt.title('@@@@@') 차트 제목설정 가능 plt.legend() 범례 설정 디폴트는 레이블명으로 설정 되고 본인이 직접 설정도 가능하다 plt.pie(데이터프레임, labels= 활용컬럼변수.index , autopct='%.nf' ,startangle = n , wedgeprops={'width' : 0.n} ) plt.title(' .. 파이썬/데이터 시각화 2022.11.28
데이터시각화 라이브러리1 카운트플롯 matplotlib/seaborn/plt/barchart 데이터 시각화 많은 데이터를 보기쉽게 시각화 하여 빅데이터를 처리하기 용이하게 해주는 과정 대표적인 데이터 시각화로 Plot 파이썬에 내장된 가장 기본적인 데이터 시각화 방법 import matplotlib.pyplot as plt x가 0~9까지 숫자라고 하고 y와 x가 같다고 했을때 plt.plot(x,y) [] plt.show() 위에 더러운거 없이 깨끗함 plt.savefig('test.jpg') 사진저장 실행중인 주피터노트북 위치에 저장 막대차트 데이터프레임, csv 에서 특정 컬럼이 카테고리컬 데이터일때 각 value 별로 몇개씩이 있는지를 차트로 표현이 가능하다 seaboen 라이브러리 사용후 카운트플로 함수를 사용 sb.countplot(data = '데이터프레임' , x='특정칼럼', c.. 파이썬/데이터 시각화 2022.11.28
파이썬 라이브러리22 pandas 데이터프레임 정렬하기/sort/ascending 데이터 정렬하기 1)오름차순 변수.sort_values('컬럼') 변수.sort_values('컬럼' , ascending = True) 변수.sort_values('컬럼' , ascending = True) ascendign(증가) = True란뜻으로 오름차순을 의미 기본적으로 어센딩이 포함된 형태가 맞지만 기본적으로 디폴트값으로 설정되어 있어서 특별하게 표시를 안해줘도 오름차순으로 정렬 된다. 이 데이터에서 경력으로 정렬을 한다면 2)내림차순 변수.sort_values('컬럼' , ascending = False) 반대로 어센딩이 거짓이라면 내림차순 3)혼합 이름은 오름차순으로 정리하고 경력은 내림차순이라면 먼저 이름과 경력을 정렬을 해보고 df.sort_values(['Employee Name','.. 파이썬/라이브러리 2022.11.25
파이썬 라이브러리21 pandas 데이터프레임 : applying 함수 데이터프레임 함수적용 데이터프레임의 데이터에 함수를 이용해서 새로운 데이터를 만들고 컬럼을만들어 저장하기 데이터를 한번에 가공하는 함수는 변수['컬럼'].apply( 함수 ) apply 함수안에 내가 적용하고 싶은 함수의 이름만 써준다 이때 함수옆에()는 빼준다. 이 데이터 프레임안에 직원의 이름이 몇글자인지 나타내는 컬럼을 작성 할때. 기존 글자수를 세는 파이썬 기본함수 len()이 있다 기존엔 문자데이터 하나를 변수에 저장하고 변수에 함수를 적용하여 글자수를 확인하는 하나하나씩 데이터를 저장했는데 df['Employee Name'].apply( len ) 0 6 1 5 2 5 3 4 Name: Employee Name, dtype: int64 df데이터프레임 안에 'Employee Name' 컬럼안 .. 파이썬/라이브러리 2022.11.25
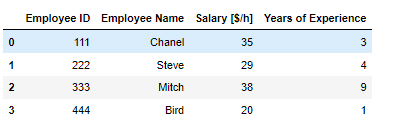
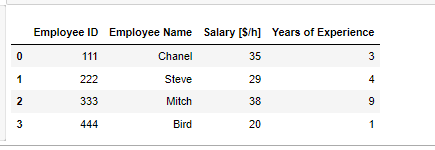
파이썬 라이브러리20 pandas 데이터프레임: boolean을 통한 데이터 추출 df = pd.DataFrame({'Employee ID':[111, 222, 333, 444], 'Employee Name':['Chanel', 'Steve', 'Mitch', 'Bird'], 'Salary [$/h]':[35, 29, 38, 20], 'Years of Experience':[3, 4 ,9, 1]}) 이러한 데이터에서 경력이 3년 이상인 데이터가 필요 하다면 경력 부분 컬럼인 'Years of Experience'을 엑세스 하고 3년이상인 데이터만 필터링 하면된다 df['Years of Experience'] >=3 Out 0 True 1 True 2 True 3 False Name: Years of Experience, dtype: bool 모든 데이터를 가져와야 하기 때문에 loc .. 파이썬/라이브러리 2022.11.24
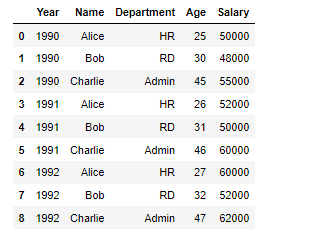
파이썬 라이브러리19 pandas 데이터프레임 : 카테고리컬 데이터 /.agg /.groupby /.unique /value_counts() 중복된 데이터 이러한 데이터가 있다면 이 데이터에서 Year 만 추출했을때 결과는? df['Year'] 값은 1990 1990 1990 1991 1991 1991 1992 1992 1992 이경우 변수['컬럼'].unique() Out array([1990, 1991, 1992], dtype=int64) 이렇게 중복이 제거된 값만 나오게 된다 묶어서 데이터 분석하기 1)그룹별 묶어서 한개 연산하기 변수.groupby('컬럼') 그룹별 묶는 명령어 자체가 함수이기 때문에 필요한 데이터를 추가로 액세스 할 수 있다. 저기서 년도별 지급한 연봉 총합을 구하라 한다면 먼저 연도별 그룹을 생각 하고 연봉을 액세스해서 총합을 구하는 메카니즘을 생각하면 편하다 df.groupby('Year') df.groupby('.. 파이썬/라이브러리 2022.11.24
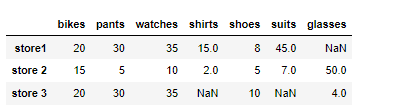
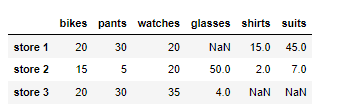
파이썬 라이브러리18 pandas 데이터프레임 : NaN데이터 처리 isna()/notna / dropna() / fillna() NaN 데이터 처리 비어있는 데이터가 어디에 있는가 확인 변수.isna() 데이터가 비어있는지 확인 변수.notna() 데이터가 채워저있는지 확인 df = pd.DataFrame(data = items2 , index = ['store1','store 2','store 3']) NaN 데이터 삭제하기 변수.dropna() NaN이 있는 데이터는 무조건 삭제 그럼 행이 삭제되어야 함. 특정 값으로 채우기 변수.fillna( 채우려는 값 ) 1.NaN데이터 처리 변수.isna() 데이터가 비어있는지 확인 변수.notna() 데이터가 채워저있는지 확인 2.NaN 데이터 삭제하기 변수.dropna() NaN이 있는 데이터는 무조건 삭제 그럼 행이 삭제되어야 함. 3.특정값으로 채우기 변수.fillna( 채우려는.. 파이썬/라이브러리 2022.11.24
파이썬 라이브러리17 pandas 데이터프레임: drop()/rename()/인덱스 바꾸기 데이터 삭제하기 행과 열 삭제하기 변수.drop('인덱스' or '컬럼' , axis = 0 or 1) 1)행 삭제 저데이터 에서 store2를 삭제한다고 하면 df = df.drop('store 2' , axis=0) 2)열삭제 df.drop(['glasses'], axis = 1) 당연히 복수 삭제도 가능하다 인덱스나 칼럼명 바꾸기 변수.rename( index or columns = { '기존이름' : '바꿀이름'} ) 인덱스명 바꾸기 먼저 바꿀 인덱스명의 칼럼을 만든후 set을 통해 인덱스에 inplace (위치 시키기) 두가지의 방법이 있음 df['name'] = ['A','B','C'] 으로 새로운 컬럼을 만들고 df = df.set_index('name') df.set_index('name'.. 파이썬/라이브러리 2022.11.24