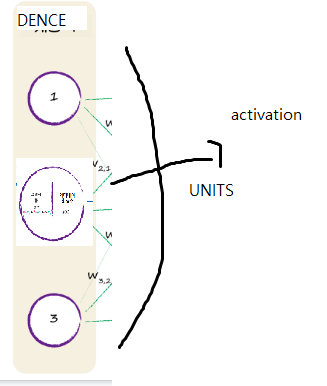
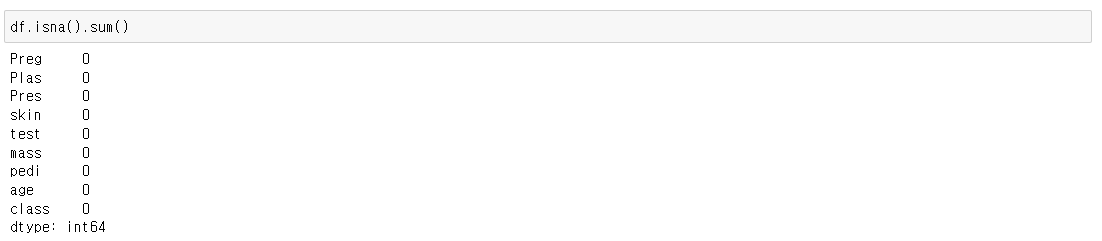
기본 필요 import문 import numpy as np import pandas as pd 머신러닝과 같은 순서를 가졌다고 생각하면 된다. from sklearn.preprocessing import OneHotEncoder , LabelEncoder from sklearn.compose import ColumnTransformer 1.nan데이터 확인 2.X,y데이터 분리 3.분리된 X데이터에서 인코딩하기 2개는 레이블 3개이상은 원핫 4.피쳐스케일링 하기 딥러닝은 무조건 피처스케일링을 해줘야 한다. from sklearn.preprocessing import MinMaxScaler 5.트레이닝 셋 나누기 from sklearn.model_selection import train_test_split..