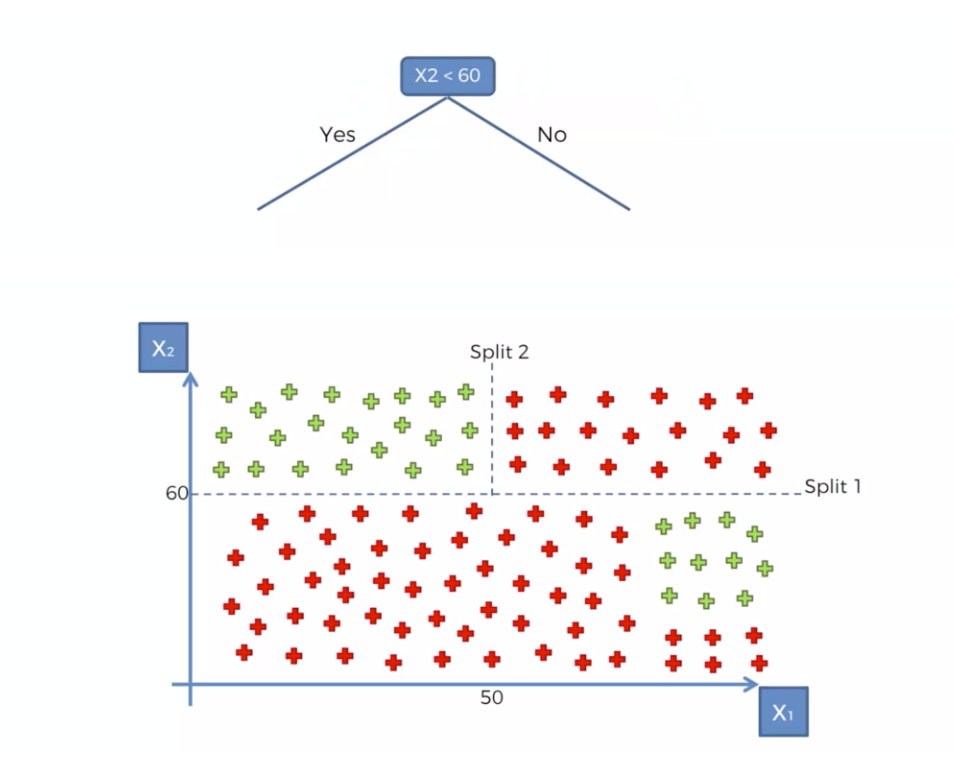
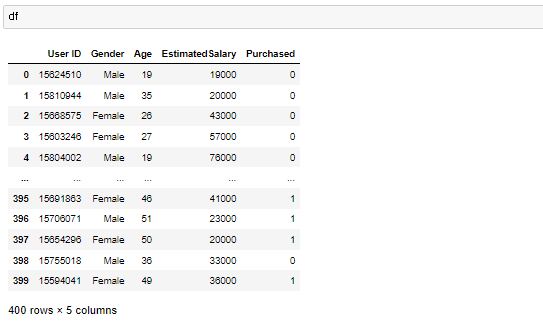
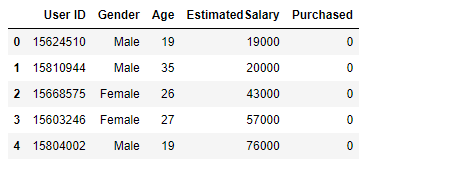Hierarchical Clustering 계층적 군집이란 가까운 두개데이터끼리 묶고 또 그 묶음과 가까운 데이터를 묶고 이런식으로 완전히 모든 데이터가 묶일때 까지 작업하는 알고리즘 유사 개채끼리 계속 군집화를 수행하다 보니 k-means와 달리 클러스팅갯수를 사전에 정하지 않아도가능하다 개체들이 결합되는 순서를 나타내는 트리형태의 구조인 덴드로그램을 통해 시각적으로 k의 갯수를 쉽게 정할 수 있다. 데이터는 수입별 구매점수를 의미 이데이터를 통해 군집화하여 최적의 그룹으로 나누기 트레이닝 기본 1. nan확인 2.x와y분리 언수퍼 바이즈드 러닝은 결과값이 없기때문에 x데이터는 존재하지만 y데이터는 존재하지 않는다 3.문자열이 있다면 숫자로 바궈주기 4.피셔츠케일링을 통해 값 맞춰주기 5.트레이닝 / ..