Logistic Regression
리그레이션(회귀분석) 이지만 독립 변수간의 관계를 구체적인 함수로 나타내어 향후 예측 모델에 사용하는 것이다.
사건발생의 가능성을 예측하는데 사용하며
확률의 문제이기 때문에 일반회귀분석과 다르게 값은 0,1로 예측을 해준다고 생각하면 된다.
그렇다면 나이와 연봉으로 물건을 구매할지 안할지 분류를 해보자
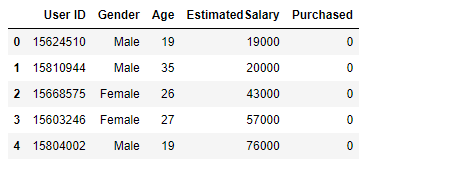
사용할 데이터프레임은 성별, 나이, 연봉, 구매유무로 나뉜 데이터로 유도
마지막 컬럼인 구매유무는 구매 했는지 안했는지 값이니까 0과 1이다
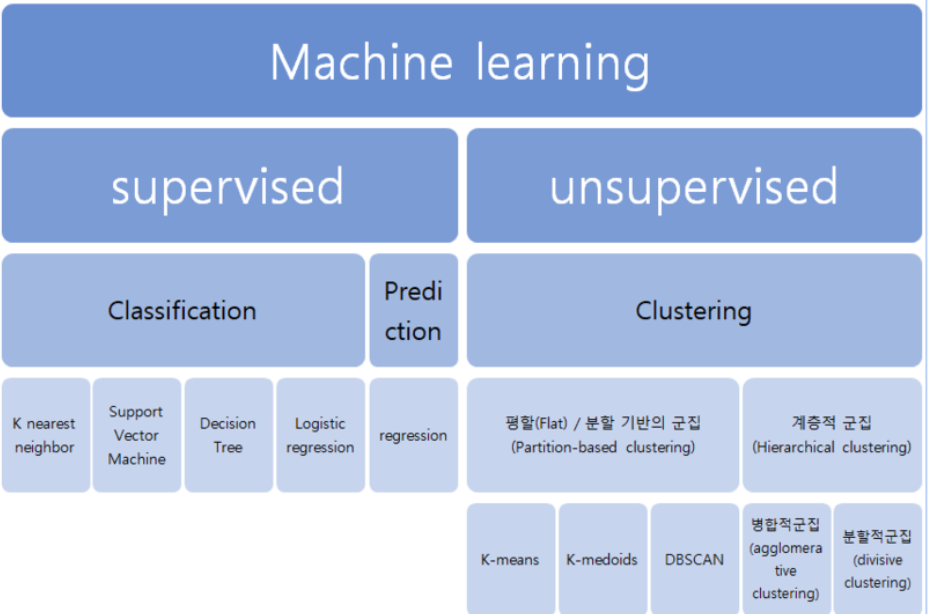
트레이닝 기본
1. nan확인
2.x와y분리
3.문자열이 있다면 숫자로 바궈주기
4.피셔츠케일링을 통해 값 맞춰주기
5.트레이닝 / 테스트 셋으로 분리시키기
----------------------------------------------------------
6.모델링하기
7.성능평가
[머신러닝0] 머신러닝의 기초(총정리) (tistory.com)
[머신러닝0] 머신러닝의 기초(총정리)
머신러닝이란 데이터를 이용하여 데이터 특성과 패턴을 학습하여 그결과 밭으로 미지의 데이터에 대한 결과값을 예측하는것 머신러닝의 종류도 다양하며 용도나 상황에 따라 이용하는 툴도 정
seonggongstory.tistory.com
1. nan확인
2.x와y분리
구매유무 가y
나이와 연봉이 x
3.문자열이 있다면 숫자로 바궈주기
4.피셔츠케일링을 통해 값 맞춰주기
로지스틱 리그레이션은 나이와 연봉의 규모가 다르기때문에 피쳐스케일링을 해줘야한다(노멀라이징)
5.트레이닝 / 테스트 셋으로 분리시키기
모델링하기
from sklearn.linear_model import LogisticRegression
변수명(classifier) = LogisticRegression(random_state=)할지말지 => 분류의 문제를위한 인공지능 라이브러리 로지스틱 리그레이션
보통 변수명은 classifier를 사용
로지스틱리그레이션 인공지능을 할 변수를 만들어 주고 그안에 학습을 위한 x값과 그에대한 결과값 변수를 넣어준다
변수명(classifier).fit(X_train, y_train)
오차를 확인하기위해 정답용 변수를 만들어주고
classifier.predict( X_test )
확인
성능평가(Confusion Matrix)
분류결과표는 0과 1로 분류하는 문제이기 때문에 행과 열이 0과 1로 표현되고 거기에 맞는 갯수를 표현해준다
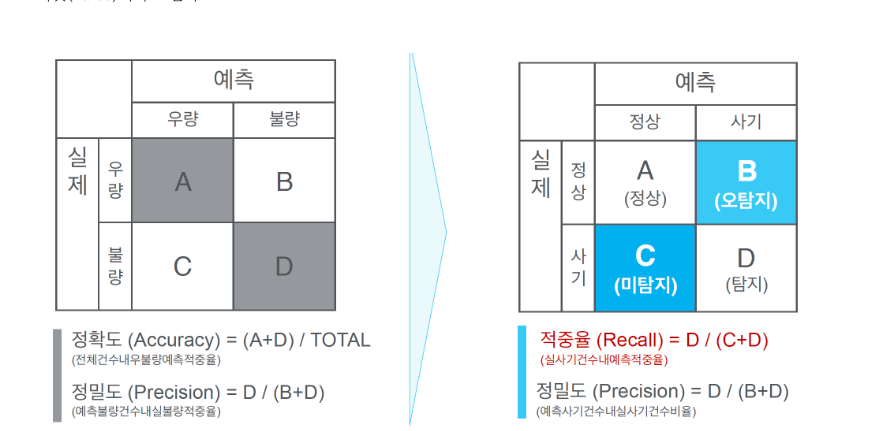
로지스틱 레그레이션에선 정확도보다 적중율이 높아야하는데
예측에서 정상을 사기로 탐지하는건 괜찮지만
사기를 정상으로 탐지를 해버리면 그건 사용할수없는 인공지능이다
from sklearn.metrics import confusion_matrixconfusion_matrix(y_test, y_pred)컨퓨전 매트릭스 함수는 답지먼저 그후에 문제지를 넣어야함

0 을 0으로예상한 갯수 52
0을 1로 예상한 갯수 6
1을 0으로 예상한 갯수 14
1을 1로 예상한 갯수 28
이 인공지능의 정확도는
(52+28) / cm.sum()
코드로는
from sklearn.metrics import accuracy_score
accuracy_score(y_test, y_pred)
클래시피케이션 리포트
from sklearn.metrics import classification_report
print( classification_report(y_test, y_pred) )
시각화
from matplotlib.colors import ListedColormap
X_set, y_set = X_test, y_test
X1, X2 = np.meshgrid(np.arange(start = X_set[:, 0].min() - 1, stop = X_set[:, 0].max() + 1, step = 0.01),
np.arange(start = X_set[:, 1].min() - 1, stop = X_set[:, 1].max() + 1, step = 0.01))
plt.figure(figsize=[10,7])
plt.contourf(X1, X2, classifier.predict(np.array([X1.ravel(), X2.ravel()]).T).reshape(X1.shape),
alpha = 0.75, cmap = ListedColormap(('red', 'green')))
plt.xlim(X1.min(), X1.max())
plt.ylim(X2.min(), X2.max())
for i, j in enumerate(np.unique(y_set)):
plt.scatter(X_set[y_set == j, 0], X_set[y_set == j, 1],
c = ListedColormap(('red', 'green'))(i), label = j)
plt.title('Classifier (Test set)')
plt.xlabel('Age')
plt.ylabel('Estimated Salary')
plt.legend()
plt.show()

| 리그레이션(회귀분석) 이지만 독립 변수간의 관계를 구체적인 함수로 나타내어 향후 예측 모델에 사용하는 것이다. 1. nan확인 2.x와y분리 구매유무 가y 나이와 연봉이 x 3.문자열이 있다면 숫자로 바궈주기 4.피셔츠케일링을 통해 값 맞춰주기 로지스틱 리그레이션은 나이와 연봉의 규모가 다르기때문에 피쳐스케일링을 해줘야한다(노멀라이징) 5.트레이닝 / 테스트 셋으로 분리시키기 모델링 from sklearn.linear_model import LogisticRegression 변수명(classifier) = LogisticRegression(random_state=1) 변수명(classifier).fit(X_train, y_train) classifier.predict( X_test ) 컨퓨전메트릭스 1)기본 from sklearn.metrics import confusion_matrix confusion_matrix(y_test, y_pred) 2)정확도 from sklearn.metrics import accuracy_score accuracy_score(y_test, y_pred) 3)시각화 from matplotlib.colors import ListedColormap X_set, y_set = X_test, y_test X1, X2 = np.meshgrid(np.arange(start = X_set[:, 0].min() - 1, stop = X_set[:, 0].max() + 1, step = 0.01), np.arange(start = X_set[:, 1].min() - 1, stop = X_set[:, 1].max() + 1, step = 0.01)) plt.figure(figsize=[10,7]) plt.contourf(X1, X2, classifier.predict(np.array([X1.ravel(), X2.ravel()]).T).reshape(X1.shape), alpha = 0.75, cmap = ListedColormap(('red', 'green'))) plt.xlim(X1.min(), X1.max()) plt.ylim(X2.min(), X2.max()) for i, j in enumerate(np.unique(y_set)): plt.scatter(X_set[y_set == j, 0], X_set[y_set == j, 1], c = ListedColormap(('red', 'green'))(i), label = j) plt.title('Classifier (Test set)') plt.xlabel('Age') plt.ylabel('Estimated Salary') plt.legend() plt.show() |
'인공지능 > 머신러닝' 카테고리의 다른 글
| [머신러닝3] K-Nearest Neighbor (0) | 2022.12.02 |
|---|---|
| 머신러닝중 샘플표본이 부족할때: oversampling (0) | 2022.12.02 |
| [머신러닝1] 수치예측: regression (0) | 2022.12.01 |
| [머신러닝0] 머신러닝의 기초(총정리) (0) | 2022.12.01 |
| Dataset traing, test set으로 나누기 (0) | 2022.12.01 |