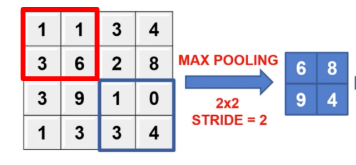
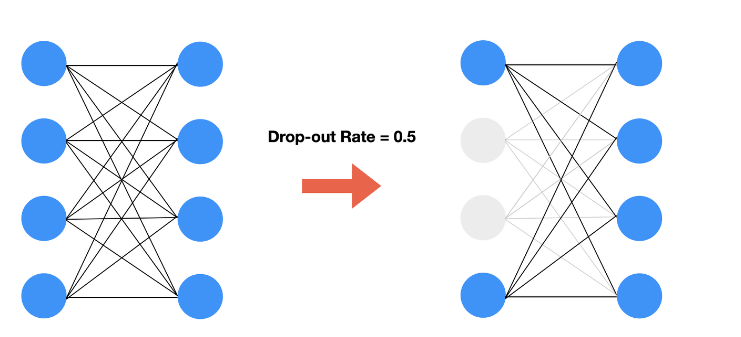
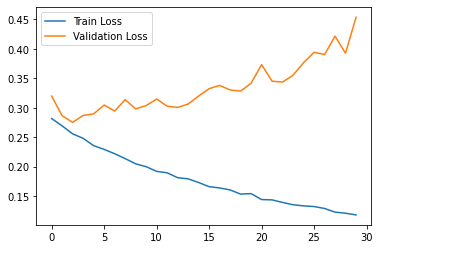
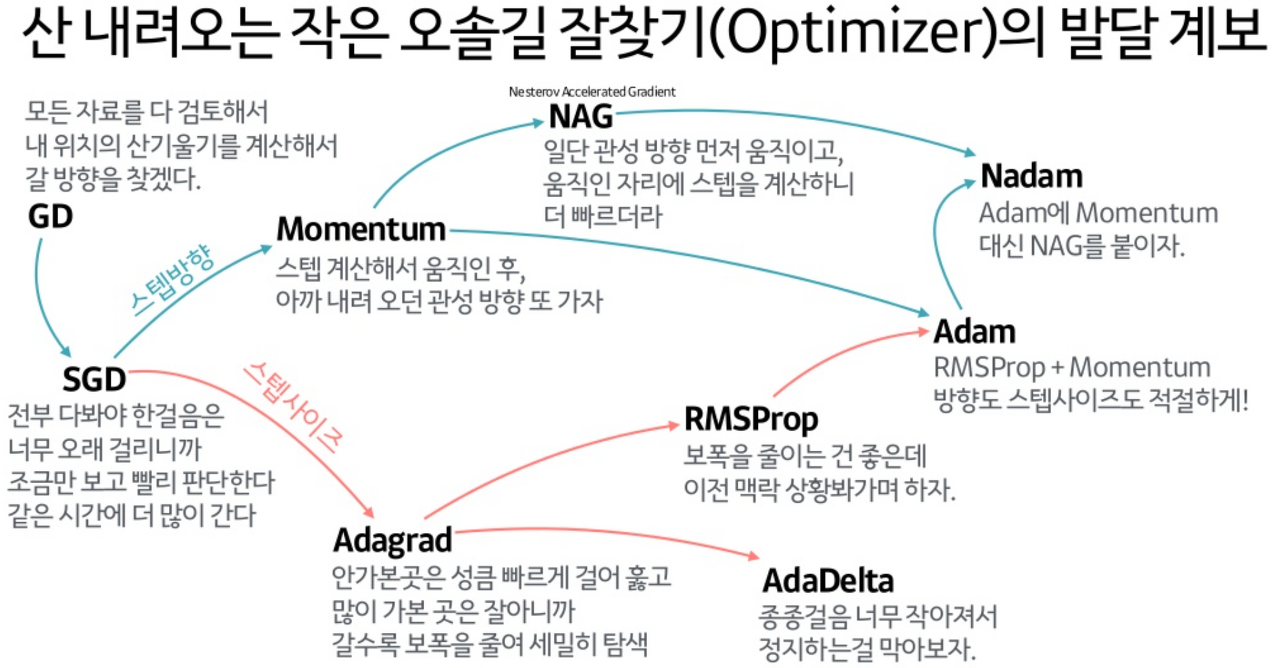
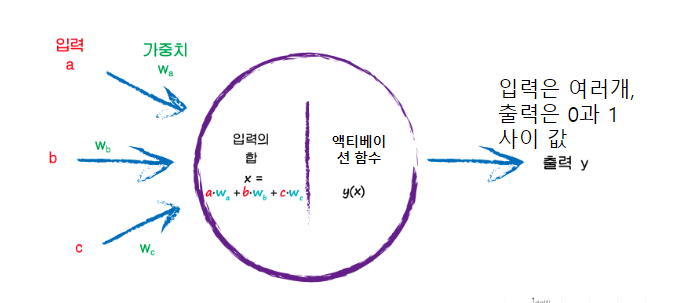
https://seonggongstory.tistory.com/151 CNN(Convolutional Neural Network) 컨볼루션 CNN이란 CNN은 이미지(영상)를 분석하기 위한 패턴을 찾아 이를 직접 학습하고, 학습한 패턴을 이용하여 이미지를 분류한다. CNN은 Convolution Layer, Pooling Layer(Sub Sampling), Fully Connected Layer 를 사용하여 seonggongstory.tistory.com pooling이란 컨볼루션을 통해 나온 피처맵의 크기를 다시 리사이징하여 새로운 레이어를 도출해내는것을 의미한다 pooling에는 최댓값을 뽑아내는 max pooling, 평균값을 뽑아내는 mean pooling등 다양한 종류가 있다. 위사진은 max..