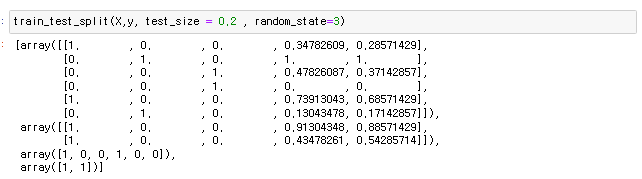
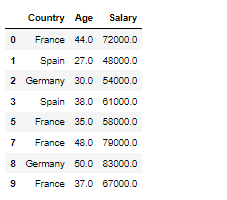
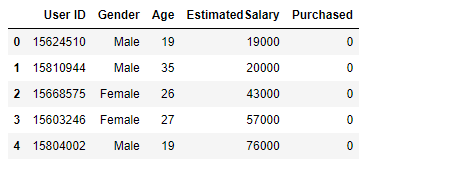Logistic Regression 리그레이션(회귀분석) 이지만 독립 변수간의 관계를 구체적인 함수로 나타내어 향후 예측 모델에 사용하는 것이다. 사건발생의 가능성을 예측하는데 사용하며 확률의 문제이기 때문에 일반회귀분석과 다르게 값은 0,1로 예측을 해준다고 생각하면 된다. 그렇다면 나이와 연봉으로 물건을 구매할지 안할지 분류를 해보자 사용할 데이터프레임은 성별, 나이, 연봉, 구매유무로 나뉜 데이터로 유도 마지막 컬럼인 구매유무는 구매 했는지 안했는지 값이니까 0과 1이다 트레이닝 기본 1. nan확인 2.x와y분리 3.문자열이 있다면 숫자로 바궈주기 4.피셔츠케일링을 통해 값 맞춰주기 5.트레이닝 / 테스트 셋으로 분리시키기 -----------------------------------------..