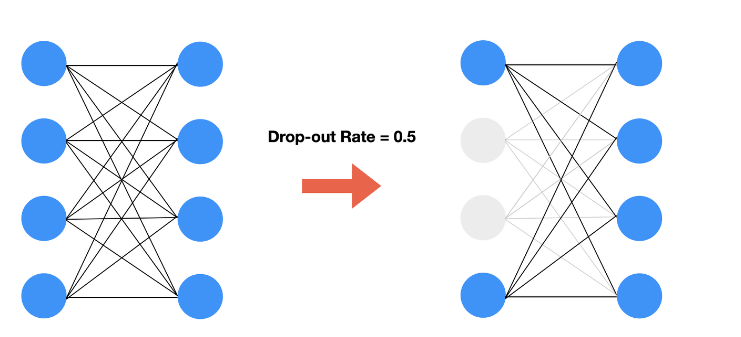
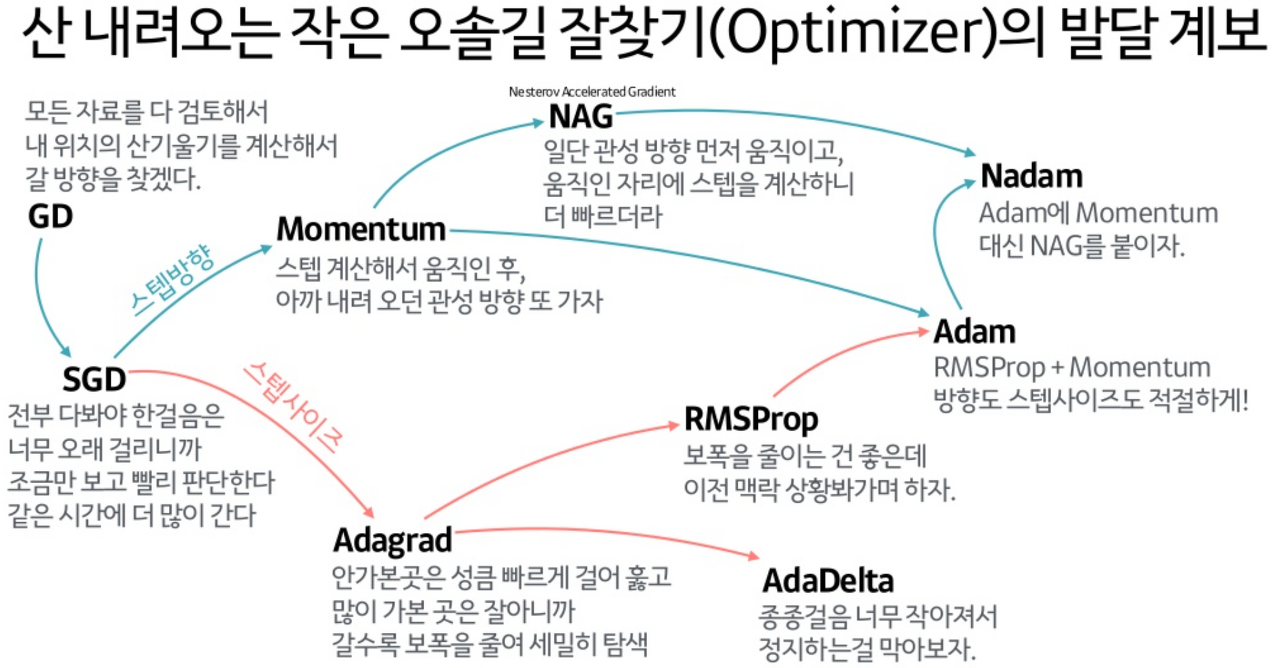
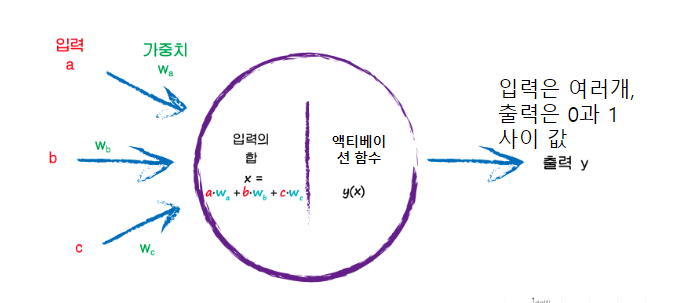
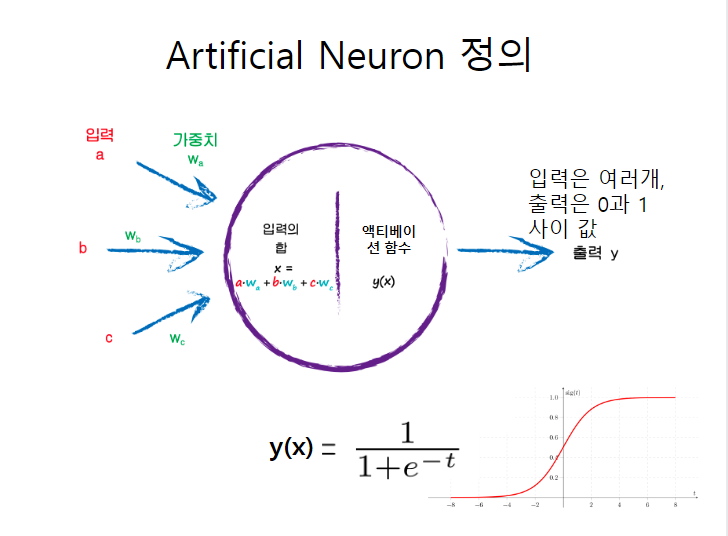
딥러닝 하이퍼 파라미터 용어 : epoch와 batch size
인공지능을 개발하고 나서 인공지능을 돌릴때 model.fit(X_train,y_train,batch_size = , epochs= ) 여기서 말하는 epoch와 batch 사이즈란? batch size 메모리의 한계와 속도 저하 때문에 대부분의 경우에는 한 번의 epoch에서 모든 데이터를 한꺼번에 집어넣을 수는 없습니다. 그래서 데이터를 나누어서 주게 되는데 이때 몇 번 나누어서 주는가를 iteration, 각 iteration마다 주는 데이터 사이즈를 batch size라고 합니다. 즉 전체 데이터를 몇개로 나누어서 학습을 할건가 epoch 한 번의 epoch는 신경망에서 전체 데이터 셋에 대해 forward pass/backward pass 과정을 거친 것을 말함. 즉, 전체 데이터 셋에 대해 한 ..