Loss Function(손실함수)
- 손실 함수란 실제값과 예측값의 차이(loss, cost)를 수치화해주는 함수이다.
- 오차가 클수록 손실 함수의 값이 크고, 오차가 작을수록 손실 함수의 값이 작아진다.
- 손실 함수의 값을 최소화 하는것이 중요.
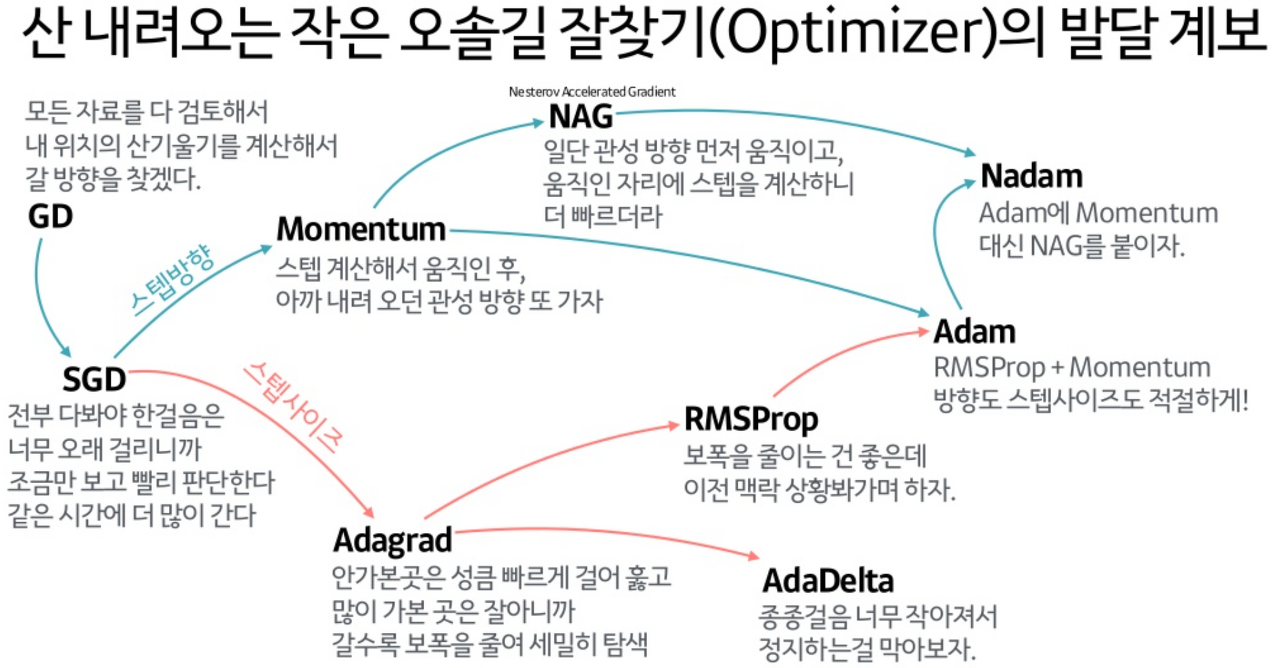
OPTIMIZER
- 옵티마이저는 손실함수의 값을 최소화 하기위해 가는 여정을 optimization 즉 최적화라고 하는데 이걸 수행하는 알고리즘을 의미한다
- 디폴트는 gd이며 최적의 가중치를 찾는 방법이라고 생각하면된다
Mean_Squared_error
예측한 값과 실제 값 사이의 평균 제곱 오차를 정의한다. 공식이 매우 간단하며, 차가 커질수록 제곱 연산으로 인해서 값이 더욱 뚜렷해진다. 그리고 제곱으로 인해서 오차가 양수이든 음수이든 누적 값을 증가시킨다.
RMSE(Root Mean Squared Error)
MSE에 루트(√)를 씌운 것으로 MSE와 기본적으로 동일하다. MSE 값은 오류의 제곱을 구하기 때문에 실제 오류 평균보다 더 커지는 특성이 있어 MSE에 루트를 씌운 RMSE 은 값의 왜곡을 줄여준다.
Binary Crossentropy
실제 레이블과 예측 레이블 간의 교차 엔트로피 손실을 계산한다. 레이블 클래스(0, 1로 가정)가 2개만 존재할 때
Binary Crossentropy를 사용하면 좋다.
Categorical Crossentropy
다중 분류 손실함수로 출력값이 one-hot encoding 된 결과로 나오고 실측 결과와의 비교시에도 실측 결과는
one-hot encoding 형태로 구성된다.
예를 들면 출력 실측값이 아래와 같은 형태(one-hot encoding)로 만들어 줘야 하는 과정을 거쳐야 한다.
[[0 0 1]
[0 1 0]
[1 0 0]] (배치 사이즈 3개인 경우)
네트웍 레이어 구성시 마지막에 Dense(3, activation='softmax') 로 3개의 클래스 각각 별로 positive 확률값이 나오게 된다.
[0.2, 0.3, 0.5]
위 네트웍 출력값과 실측값의 오차값을 계산한다.
Sparse_Categorical_Crossentropy
'categorical_entropy'처럼 다중 분류 손실함수이지만, 샘플 값은 정수형 자료이다. 예를 들어, 샘플 값이 아래와 같은 형태일 수 있다. (배치 사이즈 3개)
[0, 1, 2]
네트웍 구성은 동일하게 Dense(3, activation='softmax')로 하고 출력값도 3개가 나오게 된다.
즉, 샘플 값을 입력하는 부분에서 별도 원핫 인코딩을 하지 않고 정수값 그대로 줄 수 있다. 이런 자료를 사용할 때, 컴파일 단계에서 손실 함수만 'sparse_categorical_crossentropy'로 바꿔주면 된다.
'인공지능 > 딥러닝' 카테고리의 다른 글
| 딥러닝 파라미터 : validation_split (0) | 2022.12.28 |
|---|---|
| 텐서플로우 인공지능 컴파일중 learning rate를 옵티마이저에서 셋팅하는 코드 (0) | 2022.12.28 |
| 딥러닝 하이퍼파라미터 용어 : Dense/units/activation/input_shape (0) | 2022.12.27 |
| 딥러닝 기초 : Dummy variable trap (0) | 2022.12.27 |
| 딥러닝 하이퍼 파라미터 용어 : activation Functions (수정) (0) | 2022.12.27 |