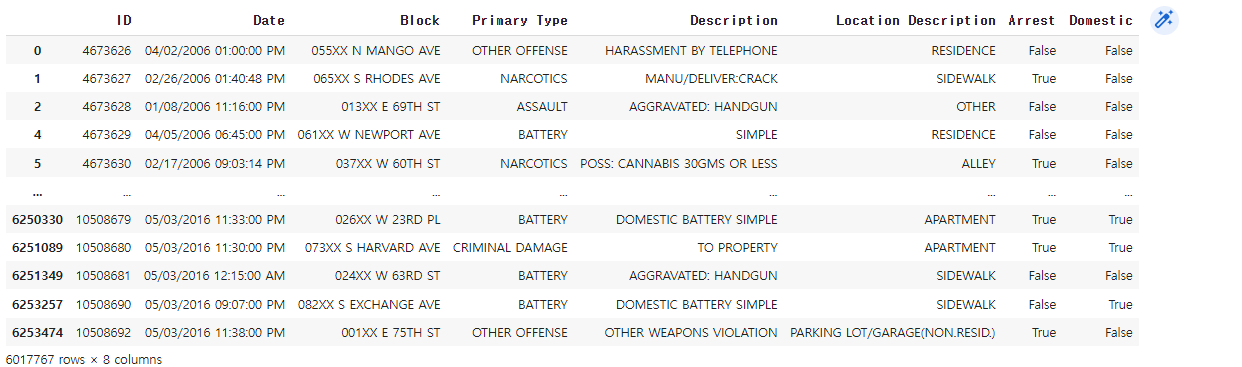
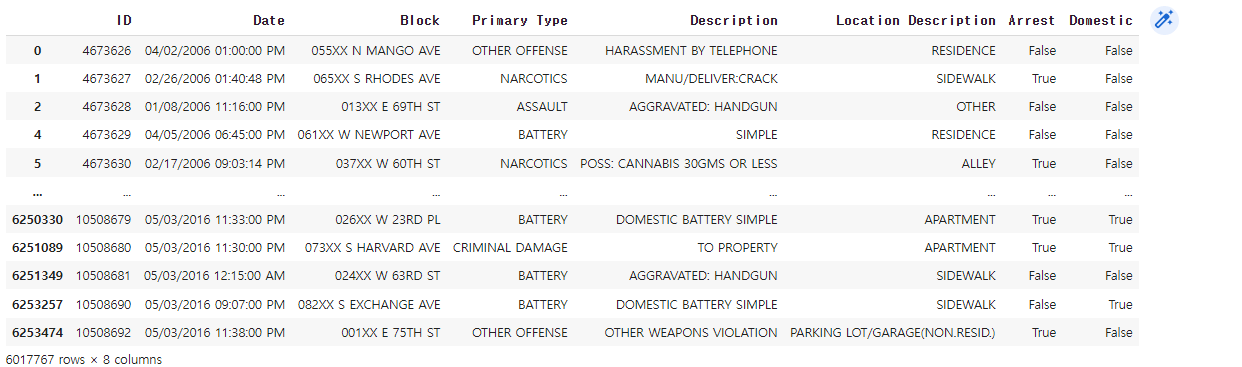
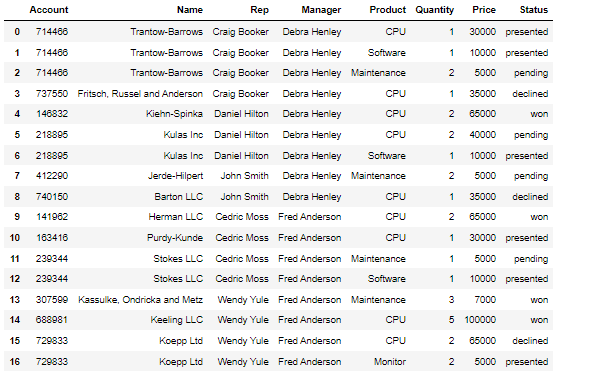
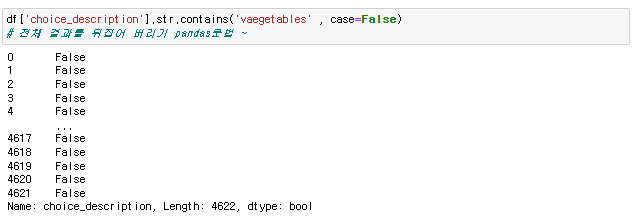
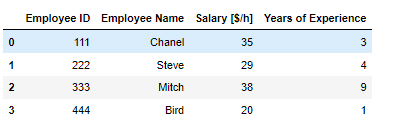
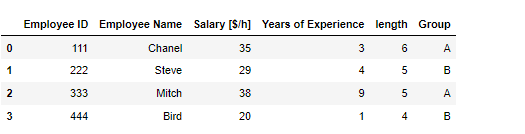시카고 범죄 현황 먼저 Date 컬럼 가공 iso 표준 시간으로 바꿔주기 chicago_df['Date'] = pd.to_datetime(chicago_df['Date'] , format = '%m/%d/%Y %I:%M:%S %p') 인덱스 설정 https://seonggongstory.tistory.com/164 pandas: resample이용하여 Time Series 년도별,월별,일별 group화 하기 시카고의 범죄상황 데이터 프레임 여기서 년도별 시간별로 월별등 시간을 쪼개서 데이터를 가공하고 싶을때 그룹바이함수를 이용해서는, 날짜 데이터로 바로 년단위 ,월단위, 일단위, 시단위, seonggongstory.tistory.com 데이터 준비 chicago_prophet = chicago_df.re..