데이터프레임 함수적용
데이터프레임의 데이터에 함수를 이용해서 새로운 데이터를 만들고 컬럼을만들어 저장하기
데이터를 한번에 가공하는 함수는
변수['컬럼'].apply( 함수 )apply 함수안에 내가 적용하고 싶은 함수의 이름만 써준다 이때 함수옆에()는 빼준다.
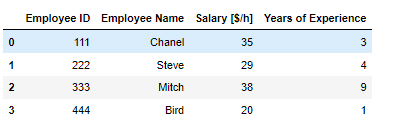
이 데이터 프레임안에 직원의 이름이 몇글자인지 나타내는 컬럼을 작성 할때.
기존 글자수를 세는 파이썬 기본함수 len()이 있다
기존엔 문자데이터 하나를 변수에 저장하고 변수에 함수를 적용하여 글자수를 확인하는 하나하나씩 데이터를 저장했는데
df['Employee Name'].apply( len )0 6
1 5
2 5
3 4
Name: Employee Name, dtype: int64df데이터프레임 안에 'Employee Name' 컬럼안 데이터에 일괄 len함수를 적용후
데이터 가공을 한다면
df['length'] = df['Employee Name'].apply( len )
문자열 함수 적용하기
Employee Name 의 이름을 모두 대문자로 바꿔서 대문자 컬럼을 작성하기.
위에 방법으로 진행시

이런 오류가 뜨는데 upper를 찾을수 없다고 오류가 나온다
upper는 파이썬의 기본 함수가 아니기고 문자열에 적용하는 함수이기 때문에
보통 데이터에 변수를 지정
df['컬럼'].str.함수()이렇게 컬럼 데이터안을 문자열로 바꿔서 데이터 표시

응용
이렇게 함수적용을 할때엔 사용자가 정의한 함수도 활용이 가능하다
시급이 30이상이면, A라고하고, 그렇지 않으면 b라고 구분해서 처리하라

grouping(20)
'B'
라고 나와야하는데
def grouping(salary) :
if salary >= 30 :
return 'A'
else :
return 'B'
그럼 이 함수를 연봉에 일괄 적용시켜야함
df['Salary [$/h]'].apply(grouping )0 A
1 B
2 A
3 B
Name: Salary [$/h], dtype: object이걸 새로운 컬럼을 만들어 적용
df['Group'] = df['Salary [$/h]'].apply(grouping 
'파이썬 > 라이브러리' 카테고리의 다른 글
| 파이썬 압축파일 푸는 방법 (0) | 2022.12.30 |
|---|---|
| 파이썬 라이브러리22 pandas 데이터프레임 정렬하기/sort/ascending (0) | 2022.11.25 |
| 파이썬 라이브러리20 pandas 데이터프레임: boolean을 통한 데이터 추출 (0) | 2022.11.24 |
| 파이썬 라이브러리19 pandas 데이터프레임 : 카테고리컬 데이터 /.agg /.groupby /.unique /value_counts() (0) | 2022.11.24 |
| 파이썬 라이브러리18 pandas 데이터프레임 : NaN데이터 처리 isna()/notna / dropna() / fillna() (0) | 2022.11.24 |