중복된 데이터
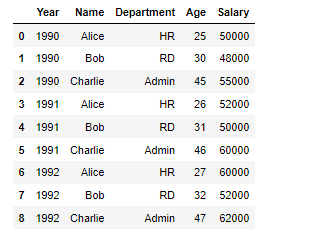
이러한 데이터가 있다면
이 데이터에서 Year 만 추출했을때 결과는?
df['Year']값은
1990 1990 1990 1991 1991 1991 1992 1992 1992이경우
변수['컬럼'].unique()
Out
array([1990, 1991, 1992], dtype=int64)이렇게 중복이 제거된 값만 나오게 된다
묶어서 데이터 분석하기
1)그룹별 묶어서 한개 연산하기
변수.groupby('컬럼')그룹별 묶는 명령어 자체가 함수이기 때문에 필요한 데이터를 추가로 액세스 할 수 있다.
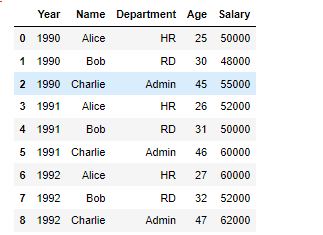
저기서 년도별 지급한 연봉 총합을 구하라 한다면
먼저 연도별 그룹을 생각 하고
연봉을 액세스해서
총합을 구하는 메카니즘을 생각하면 편하다
df.groupby('Year')
df.groupby('Year')['Salary']
df.groupby('Year')['Salary'].sum()단계별 생각을 해나가기

2) 여러개의 연산
년도별로, 연봉의 총합, 평균, 표준편차를 한번에 표시를 해야 한다면.
먼저 그룹별로 묶고
연봉을 액세스해서
그연봉의 총합 평균 표준편차를 생각
df.groupby('Year')['Salary']까진 같지만 총합,평균,표준편차는 넘파이의 함수이므로
넘파이를 먼저 import 해주고 .agg함수를 활용하면 된다.
변수.agg( ).agg함수는 여러가지 함수를 적용 시킬수 있는 장점이 있다.
import numpy as np
df.groupby('Year')['Salary'].agg( [np.sum, np.mean, np.std] )총합,평균,표준편차를 한번에 보기위해 리스트로 묶어 주면

중복되는 데이터(행)의 갯수 구하기
그룹을 나누는 컬럼은 총 몇개가 있는가
변수.groupby('컬럼')['똑같은 컬럼'].count()쉽게 표현
변수['컬럼'].value_counts()
| 1.중복데이터 변수['컬럼'].unique() → 중복값 빼기 변수['컬럼'].nunique() → 중복값이 빠진후 갯수 2.중복되는 데이터끼리 묶어서 분석하기 1)그룹별 묶어서 한개 연산하기 변수.groupby('컬럼')[필요한 칼럼] .연산 그룹별 묶는 명령어 자체가 함수이기 때문에 필요한 데이터를 추가로 액세스 할 수 있다. 2) 2개이상의 연산 .groupby('컬럼')[필요한 칼럼] .변수.agg( 연산 ) 3. 중복되는 행 갯수 구하기 변수['컬럼'].value_counts() |
'파이썬 > 라이브러리' 카테고리의 다른 글
| 파이썬 라이브러리21 pandas 데이터프레임 : applying 함수 (0) | 2022.11.25 |
|---|---|
| 파이썬 라이브러리20 pandas 데이터프레임: boolean을 통한 데이터 추출 (0) | 2022.11.24 |
| 파이썬 라이브러리18 pandas 데이터프레임 : NaN데이터 처리 isna()/notna / dropna() / fillna() (0) | 2022.11.24 |
| 파이썬 라이브러리17 pandas 데이터프레임: drop()/rename()/인덱스 바꾸기 (0) | 2022.11.24 |
| 파이썬 라이브러리16 pandas 데이터프레임: 데이터 변경/ 새로운 컬럼추가 (0) | 2022.11.24 |