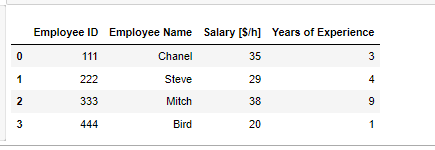
df = pd.DataFrame({'Employee ID':[111, 222, 333, 444], 'Employee Name':['Chanel', 'Steve', 'Mitch', 'Bird'], 'Salary [$/h]':[35, 29, 38, 20], 'Years of Experience':[3, 4 ,9, 1]}) 이러한 데이터에서 경력이 3년 이상인 데이터가 필요 하다면 경력 부분 컬럼인 'Years of Experience'을 엑세스 하고 3년이상인 데이터만 필터링 하면된다 df['Years of Experience'] >=3 Out 0 True 1 True 2 True 3 False Name: Years of Experience, dtype: bool 모든 데이터를 가져와야 하기 때문에 loc ..