import pandas as pd
import numpy as np데이터 가공
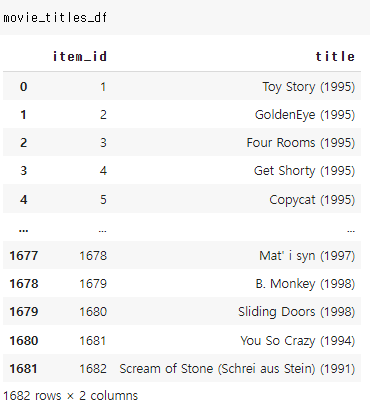
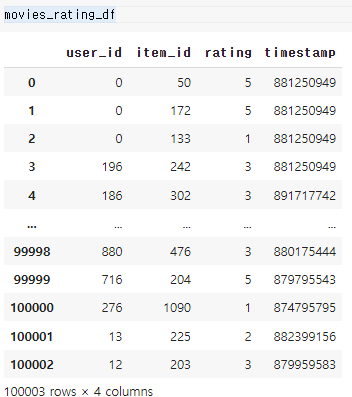
공통된 컬럼인 item_id를 토대로 합치되, 필용없는 타임스탬프 컬럼은 제거
movies_rating_df = movies_rating_df.drop('timestamp',axis=1)
movies_rating_df = pd.merge(movie_titles_df , movies_rating_df, on = 'item_id' , how='left' )여기서 how를 하지 않으면 평점을 메기지 않은 정보는 머지 되지 않기 때문에 how를 곡 해준다.

타이틀별 평균 평점을 구하기
movies_rating_df.groupby('title')['rating'].describe()
ratings_df_mean = movies_rating_df.groupby('title')['rating'].mean()
df1 = ratings_df_mean.to_frame()
df1.columns = ['mean']


ratings_df_count = movies_rating_df.groupby('title')['rating'].count()
df2 = ratings_df_count.to_frame()
df2.columns = ['count']
ratings_mean_count_df = df1.join(df2)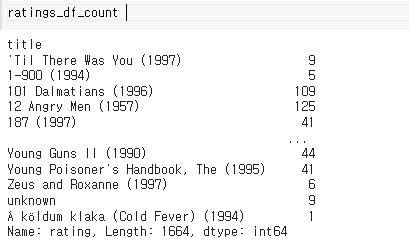

ITEM-BASED COLLABORATIVE FILTERING
데이터의 평점별 상관계수를 통해 유사 도를 측정하는 필터링을 위해
각 작품을 컬럼화 시켜서 작품별 유저가 평점을 줬는지 데이터 프레임으로 만들면된다.
이때 피벗 테이블을 활용
https://seonggongstory.tistory.com/60
pandas pivot_table
피벗테이블 컬럼값을 인덱스로 만들고, 인덱스를 중복제거하여 유니크하게 만드는 방법 pd.pivot_table(데이터프레임, index = ['컬럼명'] 이러한 데이터 프레임이 있다면 여기서 Name 컬럼에 중복되는
seonggongstory.tistory.com
df = movies_rating_df.pivot_table(index='user_id',columns='title', values= 'rating' , aggfunc='mean' )
df.corr( min_periods= 80 )min_periods란 n개의 갯수를 최소로 데이터가 있을때 평균을 내준다는것
지금 같은 상황엔 최소 80개 데이터가 있을경우 corr을 한다는 의미이다

내 별점정보로 영화 추천 하기

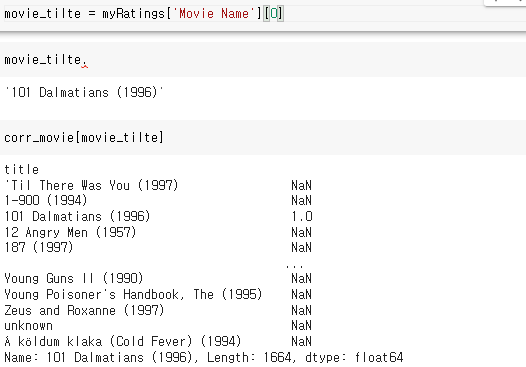
나의 별점 정보.shape는 3,2 여기에 []억세스를 할경우 첫번째 데이터인 3이 나온다 이건 내가 별점을 준 영화의 갯수를 의미하는것
그럼 몇개가 되든 차례대로 하나씩 불러와서 좋게 평가한 영화와 상관계수상 유사한 영화를 불러서 하나씩 호출해서
데이터가 있는지 억세스한후 없는데이터는 제거한다음 그 리스트를 새로운 데이터 프레임으로 만들어주면됨
similar_movies_list = pd.DataFrame()
for i in range( myRatings.shape[0] ) :
movie_title = myRatings['Movie Name'][i]
recom_movies = corr_movie[movie_title].dropna().sort_values(ascending=False).to_frame()
recom_movies.columns = ['correlation']
recom_movies['weight'] = recom_movies['correlation'] * myRatings['Ratings'][i]
similar_movies_list = similar_movies_list.append( recom_movies )
추천 받은 영화중 내가본영화와 중복되는 데이터는 삭제하고 웨이트 값으로 정렬
drop_index_list = myRatings['Movie Name'].to_list()
for name in drop_index_list :
if name in similar_movies_list.index :
similar_movies_list.drop(name,axis = 0 , inplace=True)내가 본영화 삭제
similar_movies_list.reset_index()['title'].value_counts()
similar_movies_list.groupby('title')['weight'].max().sort_values(ascending=False)
# 타이틀명으로 그룹지은다음 웨이트를 불러서 최대값만 출력해라, 물론 내림차순으로
완성
'파이썬 > 라이브러리' 카테고리의 다른 글
| 딥러닝 : prophet으로 범죄율 예측하기 (0) | 2023.01.03 |
|---|---|
| pandas: resample이용하여 Time Series 년도별,월별,일별 group화 하기 (0) | 2023.01.03 |
| 파이썬 압축파일 푸는 방법 (0) | 2022.12.30 |
| 파이썬 라이브러리22 pandas 데이터프레임 정렬하기/sort/ascending (0) | 2022.11.25 |
| 파이썬 라이브러리21 pandas 데이터프레임 : applying 함수 (0) | 2022.11.25 |