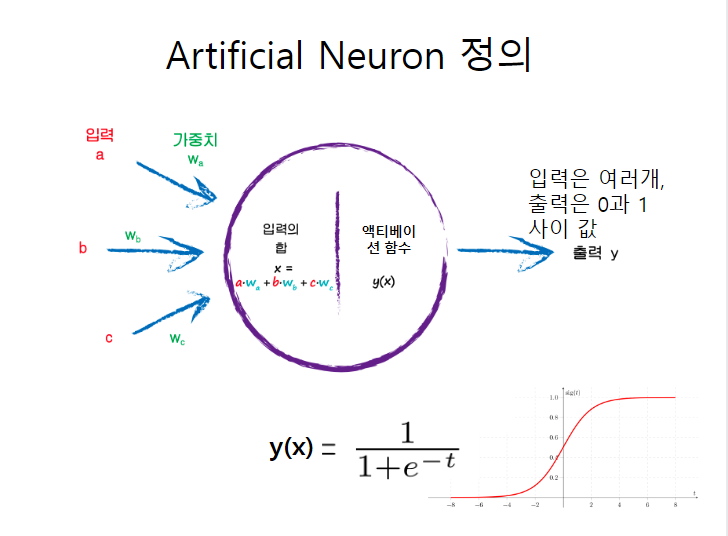
액티베이션 활성화 함수: 딥러닝 네트워크에서 노드에 입력된 값들을 비선형 함수에 통과시킨 후 다음 레이어로 전달하는데, 이 때 사용하는 함수를 활성화 함수(Activation Function)라고 한다. 선형 함수가 아니라 비선형 함수를 사용하는 이유는 딥러닝 모델의 레이어 층을 깊게 가져갈 수 있기 때문이다. 함수의 종류는 총6개로 인공지능 개발시 각각 상황에 맞게 입력해주면 된다. 분류의 문제 모델링시 0과 1로 2개로 분류하는 최종 아웃풋 레이어엔(결과물) sigmoid 함수를 사용한다. 시그모이드 함수를 사용시 특징은 0과1사이의 숫자로 결과를 내주며 확률로 계산해 리턴해준다. Logistic Classification 같은 단순하게 예,아니요 같은결과를 도출할때 유용하게 사용된다. 수치 예측 모..