Decision Tree
선하나로 분류가 불가능한 경우 데이터의 규칙을 통해 반씩 쪼개가면서 마치 스무고개하듯 가지치기를 하는 분류를 말한다
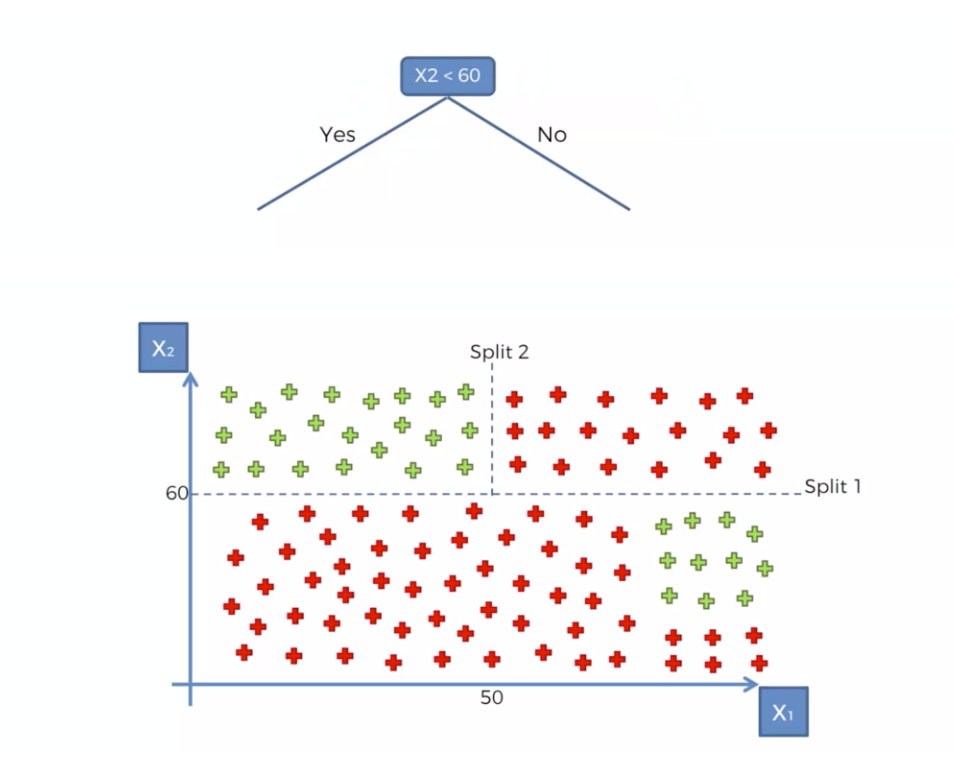
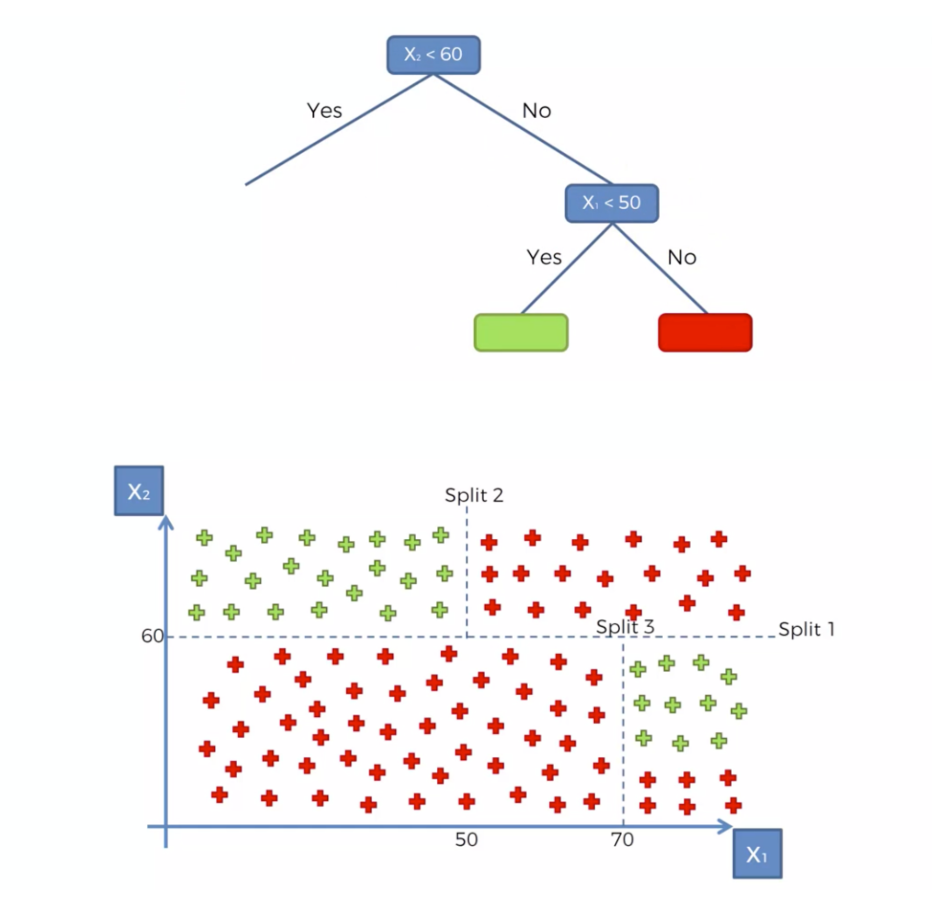
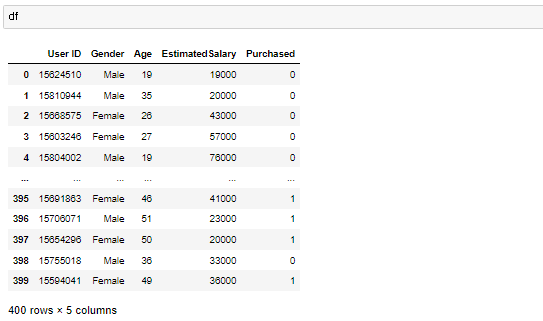
동일하게 연봉과 나이 성별, 구매여부가 있는 데이터
이데이터를 Decision Tree를 통해
새로운데이터가 나타났을때 관측값 데이터를 기준에 따라 나눠논 알고리즘을 통해 결과값 도출
트레이닝 기본
1. nan확인
2.x와y분리
3.문자열이 있다면 숫자로 바궈주기
4.피셔츠케일링을 통해 값 맞춰주기
5.트레이닝 / 테스트 셋으로 분리시키기
[머신러닝0] 머신러닝의 기초(총정리) (tistory.com)
[머신러닝0] 머신러닝의 기초(총정리)
머신러닝이란 데이터를 이용하여 데이터 특성과 패턴을 학습하여 그결과 밭으로 미지의 데이터에 대한 결과값을 예측하는것 머신러닝의 종류도 다양하며 용도나 상황에 따라 이용하는 툴도 정
seonggongstory.tistory.com
6.모델링하기
from sklearn.tree import DecisionTreeClassifier
classifier = DecisionTreeClassifier()
classifier.fit(X_train, y_train)
7.성능평가
컨퓨전매트릭스
cm = confusion_matrix(y_test, y_pred)accuracy_score(y_test, y_pred)
시각화
X_set, y_set = X_test, y_test
X1, X2 = np.meshgrid(np.arange(start = X_set[:, 0].min() - 1, stop = X_set[:, 0].max() + 1, step = 0.01),
np.arange(start = X_set[:, 1].min() - 1, stop = X_set[:, 1].max() + 1, step = 0.01))
plt.figure(figsize=[10,7])
plt.contourf(X1, X2, classifier.predict(np.array([X1.ravel(), X2.ravel()]).T).reshape(X1.shape),
alpha = 0.75, cmap = ListedColormap(('red', 'green')))
plt.xlim(X1.min(), X1.max())
plt.ylim(X2.min(), X2.max())
for i, j in enumerate(np.unique(y_set)):
plt.scatter(X_set[y_set == j, 0], X_set[y_set == j, 1],
c = ListedColormap(('red', 'green'))(i), label = j)
Random Forest
의사 결정 트리는 의사 결정에 사용하는 규칙을 만들어 가지치기를 하지만
랜덤 포레스트는 무작위로 선택하고 데이터를 관찰한후 의사 결정 트리의 포리스트를 만든 다음 결과를 평균화한다
많은 수의 상관없는 데이터들을 묶어서 평균화하여 의사결정 나무보다 더 정확도를 높인다
from sklearn.ensemble import RandomForestClassifier
classifier2 = RandomForestClassifier(n_estimators=n)
classifier2.fit(X_train, y_train)파라미터 n_estimators는
결정을 지을 나무의 갯수를 지정하며 디폴트는 10개다
상관없는 결정 무리가 늘어나기때문에 정확도가 올라감
컨퓨전 테스트후

실제로 정확도가 올라간다
| 디시젼트리 선하나로 분류가 불가능한 경우 데이터의 규칙을 통해 반씩 쪼개가면서 마치 스무고개하듯 가지치기를 하는 분류를 말한다 모델링 from sklearn.tree import DecisionTreeClassifier classifier = DecisionTreeClassifier() classifier.fit(X_train, y_train) 랜덤포레스트 모델링 from sklearn.ensemble import RandomForestClassifier |
'인공지능 > 머신러닝' 카테고리의 다른 글
| [머신러닝7] 계층적 군집 알고리즘: Hierarchical Clustering / Dendogram (0) | 2022.12.05 |
|---|---|
| [머신러닝6] 데이터평균군집 알고리즘: K-means (0) | 2022.12.05 |
| 가장 적합한 매개변수찾기: grid search (0) | 2022.12.02 |
| [머신러닝4] Support Vector Machine (0) | 2022.12.02 |
| [머신러닝3] K-Nearest Neighbor (0) | 2022.12.02 |