머신러닝이란
데이터를 이용하여 데이터 특성과 패턴을 학습하여 그결과 밭으로 미지의 데이터에 대한 결과값을 예측하는것
머신러닝의 종류도 다양하며 용도나 상황에 따라 이용하는 툴도 정말 다양하다
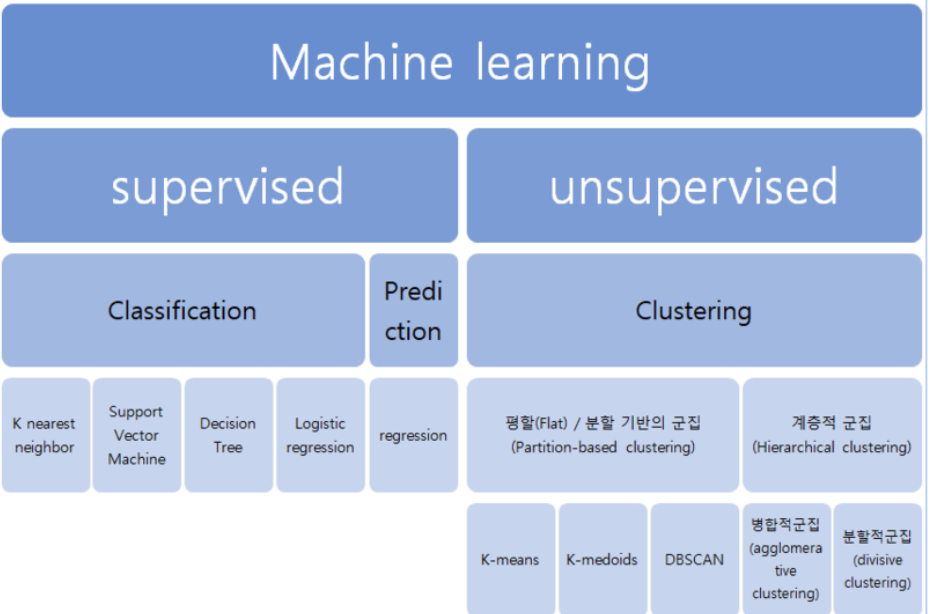
먼저 머신러닝의 큰 갈래에는 Supervised러닝과 unsupervised 러닝이 있는데
데이터의 결과값을 도출해내느냐, 데이터를 분류를 하느냐라고 생각하면 편하다.
먼저 supervised 러닝은 새로운 데이터 결과값을 도출해내기 위해 당연히 학습시킬 기존데이터가 존재해야하고
이 품종에대한 데이터를 레이블이라고 표현한다.
이 supervised의 러닝엔 또 두가지 유형으로 나뉘어지는데
연속형 변수들에 대해 두 변수 사이의 모형을 구한 뒤 적합도를 측정해 내는 분석 방법인 regression과
기존에 존재하는 데이터의 관계를 파악하고, 새롭게 관측된 데이터의 카테고리를 스스로 판별하는 classification이 있다.
머신러닝을 하기위해선
트레이닝 기본
1. nan확인
2.x와y분리
3.문자열이 있다면 숫자로 바궈주기
4.피셔츠케일링을 통해 값 맞춰주기
5.트레이닝 / 테스트 셋으로 분리시키기
----------------------------------------------------------
6.모델링하기
7.성능평가
1 ~ 5 번 까지는 모두 같은 과정이며 6~7까지는 각각 머신러닝에따라 평가방법이나 라이브러리가 조금씩 다른 특징을 지니고 있다.
1. NaN 처리
데이터에 빈공간이 있으면 데이터 수집이 힘든 점이 있기때문에 NaN이 있는지 꼭 확인을 해야한다
df.isna().sum()
이렇게 비어있는 데이터가 있을경우 보통 2가지 방법을 활용하는데
1) 채우기
단순하게 0으로 채울수도 있지만 평균을 채워 넣어야 데이터를 모아서 러닝할때 전체값이 훼손당할 가능성이 줄어듬
df.fillna( df.mean(numeric_only=True) )
2)삭제하기
하지만 nan 데이터의 양이 많아지면 평균값을 넣어도 훼손되는건 마찬가지이기 때문에
보통은 데이터를 삭제해준다
df.dropna(inplace=True)판다스의 함수를 이용해 쉽게 제거
데이터 분리
Dataset traing, test set으로 나누기 (tistory.com)
Dataset traing, test set으로 나누기
어떠한 결과를 도출해내기 위한 머신러닝을 위해 도출해내려는 값y 학습시킬 데이터를 x로 표현하는데 머신러닝을 돌렸을때 학습용만 데이터가 있다면 나중에 결과값이 정확하지 않는경우가
seonggongstory.tistory.com
레이블링
문자의 수치화,데이터분리 : LableEncoder (tistory.com)
문자의 수치화,데이터분리 : LableEncoder
머신러닝을 통한 학습으로 새로운데이터를 얻으려고 할때 기존데이터를 방정식에 대입하기 위해서는 모든데이터가 숫자로 되어 이썽야한다. 문자열 데이터는 숫자로 바궈줘야 하는데 그때 사
seonggongstory.tistory.com
문자 수치화,데이터분리: OneHotEncoder (tistory.com)
문자 수치화,데이터분리: OneHotEncoder
카데고리컬 데이터가 3개이상이면 머신러닝의 효율이 떨어지는데 레이블인코딩은 이런점에서 취약하다 그럴때 사용하는 방식은 원핫 인코딩하는것 원핫 인코딩이란 3개이상의 카테고리컬 데
seonggongstory.tistory.com
데이터 전처리(Feature Scaling)
유클리디언 디스턴스로 오차를 줄여 나가는데, 하나의 변수는 오차가 크고, 하나의 변수는 오차가 작으면, 나중에 오차를 수정할때 편중되게 된다. 따라서 값의 레인지를 맞춰줘야 정확히 트레이닝 된다.
그래서 서로다른 변수의 값 범위를 각 기준에 맞게 일정 수준 범위로 맞춰주는 작업임
피쳐스케일링은 크게 2가지 방법이 있는데

표준화는
from sklearn.preprocessing import StandardScaler, MinMaxScaler
1)표준화(Standardization)
기본값에서 평균을 빼고 표준편차로 나눈값
보통 Support Vector Machine, Linear Regression, Logistic Regression 에서 사용
s_scaler_x = StandardScaler()
s_scaler_x.fit_transform( X )
2)정규화(Normalizing)
실제값을 최대1에서 최소0으로 맞춰논 값
m_scaler_x = MinMaxScaler()
m_scaler_x.fit_transform(X)
테스트용과 트레이닝용으로 나누기
from sklearn.model_selection import train_test_split
train_test_split(X,y, test_size = 0.n , random_state=)파라미터
testsize는 내가준 데이터에서 트레이닝 용으로 사용할 비율을 의미
random state는 시드값
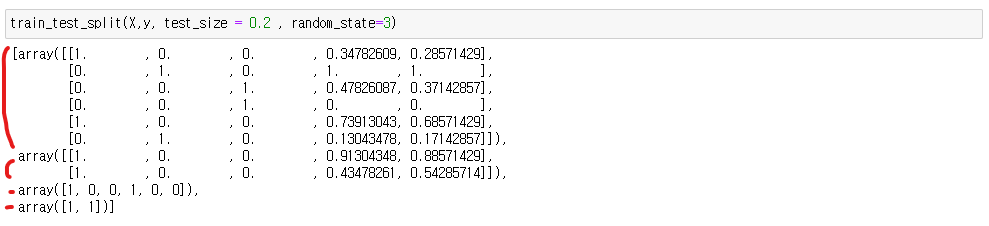
4개의 묶음이 나오는데
첫번째는 X값 데이터 트레이닝용
X값 테스트
y값 트레이닝 학습용
Y값 테스트(정답지)

이렇게 변수를 만들어 준다
| 1. nan확인 df.isna().sum() 1) 채우기 df.fillna( df.mean(numeric_only=True) ) 2)삭제하기 df.dropna() 2.x와y분리 from sklearn.model_selection import train_test_split train_test_split(X,y, test_size = 0.n , random_state=n) 3.문자열이 있다면 숫자로 바궈주기 1)레이블 from sklearn.preprocessing import LabelEncoder 변수명 = LabelEncoder() 인코더변수.fit_transform(바꿔줄 컬럼 ) 2) 원핫 인코더 from sklearn.preprocessing import OneHotEncoder from sklearn.compose import ColumnTransformer ColumnTransformer( [ ('인코더이름',OneHotEncoder(),[인덱스] ) ] , remainder ='passthrough' ) ct.fit_transform( 바꿔줄데이터프레임 ) 4.피처스케일링을 통해 값 맞춰주기(데이터 전처리) from sklearn.preprocessing import StandardScaler, MinMaxScaler 1)표준화 s_scaler_x = StandardScaler() s_scaler_x.fit_transform( X ) Support Vector Machine, Linear Regression, Logistic Regression 2)정규화 m_scaler_x = MinMaxScaler() m_scaler_x.fit_transform(X) 5.트레이닝 / 테스트 셋으로 분리시키기 from sklearn.model_selection import train_test_split train_test_split(X,y, test_size = , random_state=) |
'인공지능 > 머신러닝' 카테고리의 다른 글
| [머신러닝2] 범주형 변수예측: Logistic Regression (0) | 2022.12.02 |
|---|---|
| [머신러닝1] 수치예측: regression (0) | 2022.12.01 |
| Dataset traing, test set으로 나누기 (0) | 2022.12.01 |
| 문자 수치화,데이터분리: OneHotEncoder (0) | 2022.12.01 |
| 문자의 수치화,데이터분리 : LableEncoder (0) | 2022.12.01 |