regression
regression은 y=ax+b라는 직선 방정식으로 봤을때
x와 y값의 데이터를 학습시켜서 a와 b를 찾아 내는것이 이 머신러닝의 목표
직선의 방정식을 컴퓨터가 계산하여 직선의 기울기와 Y절편을 구해줌
계수를 찾아내고 예측치와 실제값의 오차를 줄여나가는것

예를 들면 y가 연봉 x가 연차라고 생각하면 편하다.
그럼 이러한 데이터들을 모아 연차별 연봉을예측함
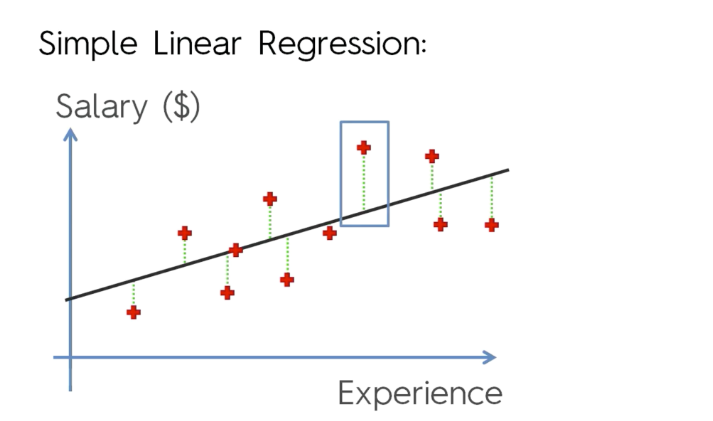
이런식으로 어떤 데이터가 예측된 직선에 가까운 값을 찾아준다 벌어진 오차만큼의 간격을
많은 데이터를 통해 줄여나가는것
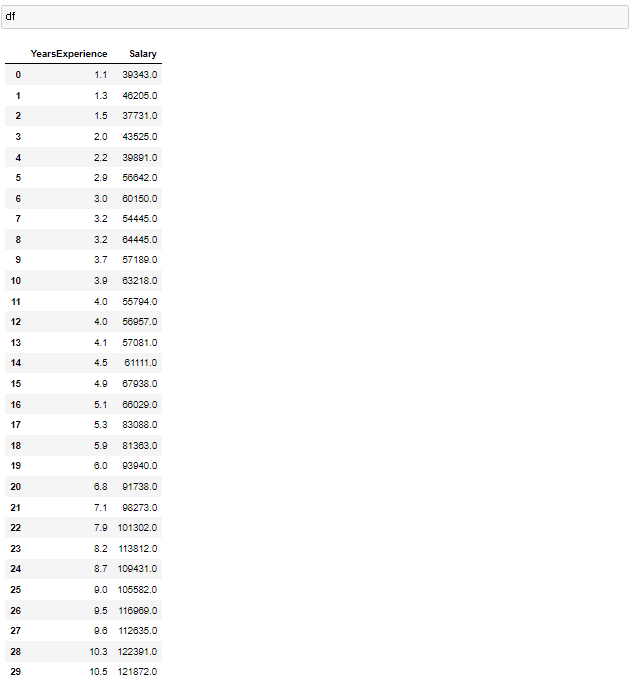
연차별 연봉데이터가 있을때
특정연차의 연봉을 예상하기
x와 y데이터로 분리 할때 내가 알고싶은 값이 연봉이니까 연봉이 y
X = df.loc[ : ,'YearsExperience' ].to_frame()여기서 to_frame을 해주는 이유는 한가지 컬럼밖에 없어서 결과값이 판다스 시리즈로 나온다
x는 2차원이여야 한다
4.피쳐스케일링
리니얼 리그레션은 자체적으로 피쳐스케일링을 해줘서 직접 피쳐스케일링을 해줄 필요가 없다
5.셋 분리

리니얼 리그레션 모델링 하기
from sklearn.linear_model import LinearRegression
regressor = LinearRegression()학습시킬 인공지능을 변수에 넣어놓고 아까 분리시킨 x트레인과 y트레인을 넣어 학습 시켜줌
리니어리그레션변수.fit(X트레인 , y트레인 )

이 인공지능으로 리니어는 랜덤으로 ab세팅하고 fit함수실행시 x트레인과 y트레인 가지고 오차를 찾아서 오차가 최소값이 나오게 ab값을 세팅해줌
그렇게 해서 찾아낸 a와 b의 계수
변수.coef_
변수.intercept_coef은 a intercept는 b
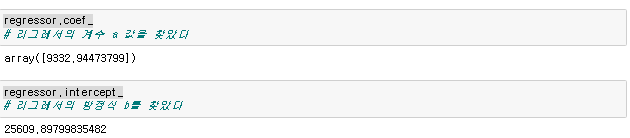
이뜻은
y=ax+b 이기 때문에 y= 9332.94473799 *x + 25609.89799835482 가됨
예측한값을 변수에 넣어주고
예상변수 = 인공지능변수.predict(X_test)
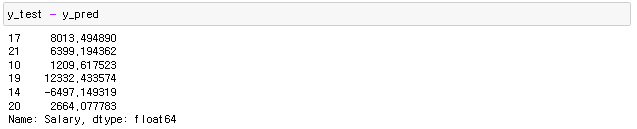
실제 연봉값과 예상값의 오차를 구하면됨
오차란 실제값 - 예측값
똑똑한 인공지능은 오차가 적은것을 의미한다.

성능 측정을 하기 위해서는
그냥 오차를 사용하면, 부호 때문에, 계산이 안됨 (헷갈림 오차가 +10 -10 나는걸 더하면 오차가 0이 되머리는 이상함)
그래서 성능측정을 위해서는, 부호를 없애기 위해서 오차를 제곱해준다

오차를 구하고, 오차를 제곱한후에, 평균을 구함
mean squard error => MSE
MSE로 성능평가해서, 수치가 작을수록 좋은 인공지능이라는 뜻

차트로 예측치와 비교
리니얼 리그레션 from sklearn.linear_model import LinearRegression 변수 = LinearRegression() 리니어리그레션변수.fit(X트레인 , y트레인 ) 변수.coef_ 변수.intercept_ 예측 예상변수 = 인공지능변수.predict(X_test) y_test - y_pred 로 오차구하기 실제값 - 예측값 error ** 2 차트로 실제와 예측값 비교 plt.plot(y_test.values) plt.plot(y_pred) plt.legend( ['Real','pred']) plt.show() |
'인공지능 > 머신러닝' 카테고리의 다른 글
| 머신러닝중 샘플표본이 부족할때: oversampling (0) | 2022.12.02 |
|---|---|
| [머신러닝2] 범주형 변수예측: Logistic Regression (0) | 2022.12.02 |
| [머신러닝0] 머신러닝의 기초(총정리) (0) | 2022.12.01 |
| Dataset traing, test set으로 나누기 (0) | 2022.12.01 |
| 문자 수치화,데이터분리: OneHotEncoder (0) | 2022.12.01 |