카데고리컬 데이터가 3개이상이면 머신러닝의 효율이 떨어지는데
레이블인코딩은 이런점에서 취약하다
그럴때 사용하는 방식은
원핫 인코딩하는것
원핫 인코딩이란
3개이상의 카테고리컬 데이터를 전부 컬럼화 시켜서 하나의 1과 0으로 표현하는것
가령
컨트리라는 컬럼에 프랑스 독일 스페인이 있다면
France Germany Spain
1 0 0
0 1 0
0 0 1
각 각에 해당되는 데이터에 1을 배당해서 컬럼화 시킴
이런식으로 Hot(1)이 one개 있다는 뜻
원핫인코딩을 위해선
from sklearn.preprocessing import OneHotEncoderfrom sklearn.compose import ColumnTransformerColumnTransformer( [ ('인코더이름',OneHotEncoder(),[인덱스] ) ] , remainder ='passthrough' )컬럼을 바꾸는함수 columnTransformer (인코더이름, 어떤형식, [바꿀 데이터의 위치]) ,
remainder => 바꿀컬럼 인덱스외에 남은컬럼
passthroygh => 패스 하겠다.
저 묶음을 변수로 저장한 후에
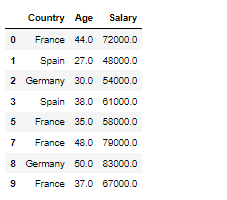
이 데이터에서 카테고리컬 데이터인 컨트리 컬럼을 원핫 인코더로 바꾸려면 인덱스는 0번
ct = ColumnTransformer( [ ('encoder',OneHotEncoder(),[0] ) ] , remainder ='passthrough' )
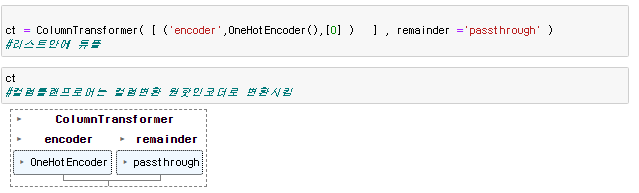
ct.fit_transform( 바꿔줄데이터프레임 )

원핫 인코더로 변환되면 데이터는 무조건 앞으로 온다.
1,0,0,44,72로 바뀐걸 볼 수있다.
| 원핫 인코더 from sklearn.preprocessing import OneHotEncoder from sklearn.compose import ColumnTransformer ColumnTransformer( [ ('인코더이름',OneHotEncoder(),[인덱스] ) ] , remainder ='passthrough' ) ct.fit_transform( 바꿔줄데이터프레임 ) |
'인공지능 > 머신러닝' 카테고리의 다른 글
| [머신러닝2] 범주형 변수예측: Logistic Regression (0) | 2022.12.02 |
|---|---|
| [머신러닝1] 수치예측: regression (0) | 2022.12.01 |
| [머신러닝0] 머신러닝의 기초(총정리) (0) | 2022.12.01 |
| Dataset traing, test set으로 나누기 (0) | 2022.12.01 |
| 문자의 수치화,데이터분리 : LableEncoder (0) | 2022.12.01 |