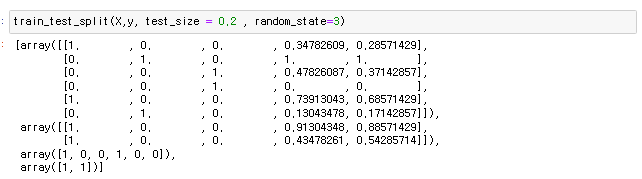
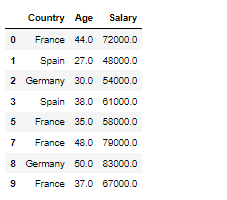
서포트 벡터 머신 서포트 벡터머신이란 데이터를 분류하는 선중에 마진을 최대화 하는 경계면을 찾아서 나눠준다 마진이란 데이터를 분류해서 나눴을때 그 분류에서 가장 먼 데이터끼리의 사이를 의미함 가장 분류가 잘 나타나는 것들끼리 선에서 멀어지고 구분하기 힘든 데이터는 클래서파이어에 가까워짐 마진을 최대화 하여 분류하기 때문에 특이한것 까지 비슷한 부류로 묶는데에 많이 사용 동일하게 연봉과 나이 성별, 구매여부가 있는 데이터 이데이터를 KNN 머신러닝을 통해 새로운데이터가 나타났을때 어느쪽으로 분류를 할지 정하기 트레이닝 기본 1. nan확인 2.x와y분리 3.문자열이 있다면 숫자로 바궈주기 4.피셔츠케일링을 통해 값 맞춰주기 5.트레이닝 / 테스트 셋으로 분리시키기 [머신러닝0] 머신러닝의 기초(총정리) (..