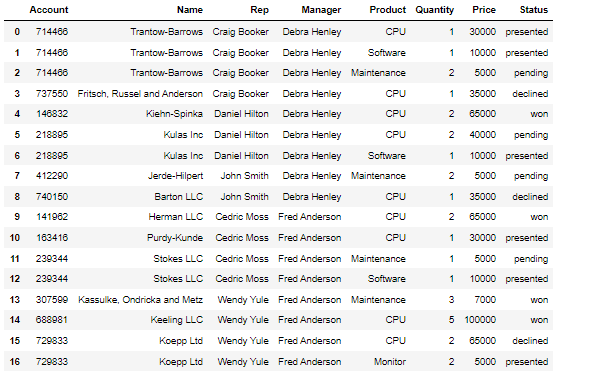
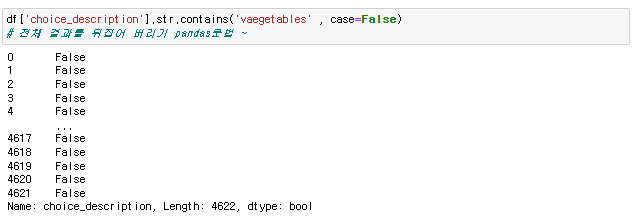
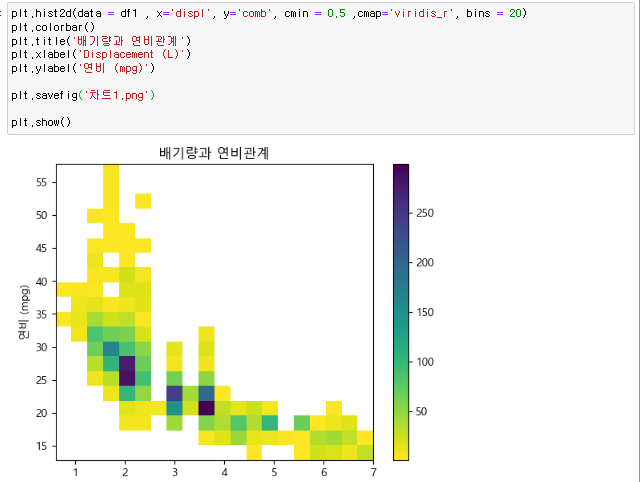
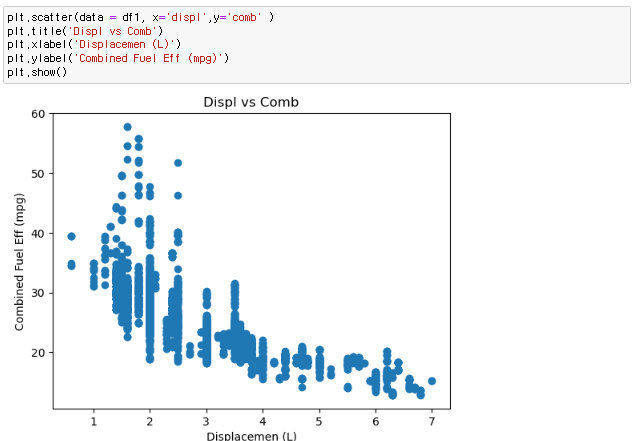
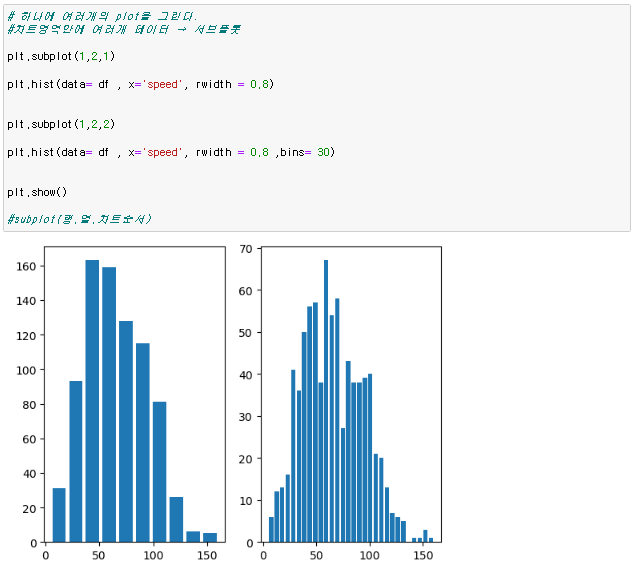
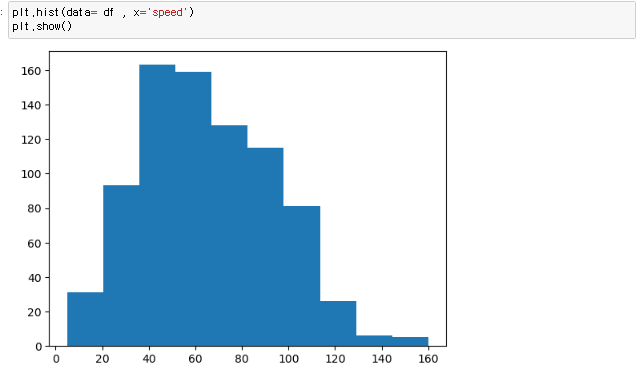
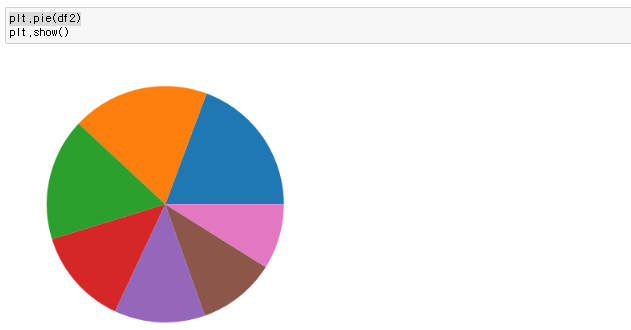
[numpy] datetime64 기존의 파이썬 datetime 을 보강하기 위해, date 의 array 도 처리할 수 있게 numpy 에서 64-bit 로 처리하도록 라이브러리를 강화한 형태 np.array('날짜', dtype = np.datetime64) 이렇게 datetiem64를 활용할경우 연산이 훨씬 편해진다 당연히 넘파이 함수이기 때문에 arange와 연산도 가능하다 판다스 to_datetime 문자열로 되어있는 날짜의 리스트를 한번에 파이썬의 날짜형식으로 변환하는 함수 pd.to_datetime(date_list) 그냥 눈으로 봤을때는 날짜 형식이지만 실제로는 문자열로 되어있는 데이터를 쉽게 날짜로 바꿔버림 전체 데이터를 날짜로 바꿨기 때문에 모든 데이터를 쉽게 가공할수있음 [pandas..