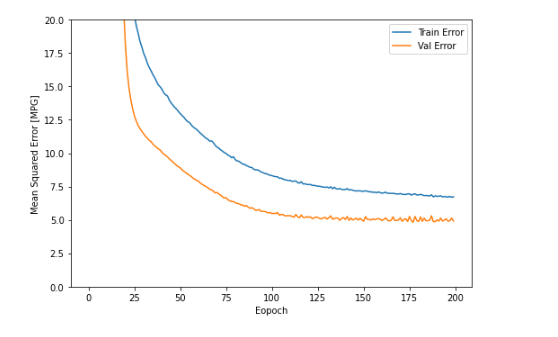
에포크 히스토리를 차트로 확인을 해보니 수백번정도 이후에는 거의 모델이 향상하지 않는 모습이 보인다. 이런경우 시간의 효율을 높이기 위해 call back을 활용해 지정된 에포크 횟수 동안 성능향상이 없으면 자동으로 훈련을 멈추고 결과를 내주는 함수를 만들어서 활용하면 된다. callback이란 보통 일반적으로 내가 쉬프트 엔터처서 함수를 실행시킴 이건 콜백이 아님, 내가 만든 함수를, 프레임워크가 실행시켜주는 것을 의미 tf.keras.callbacks.EarlyStopping( 조건) early_stop = tf.keras.callbacks.EarlyStopping(monitor = 'val_loss', patience= 10) val_loss를 모니터하면서 10번의 에포크동안 성능 향상이 없을 경우..