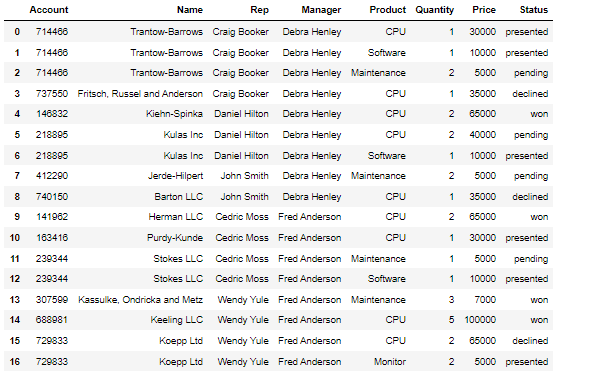
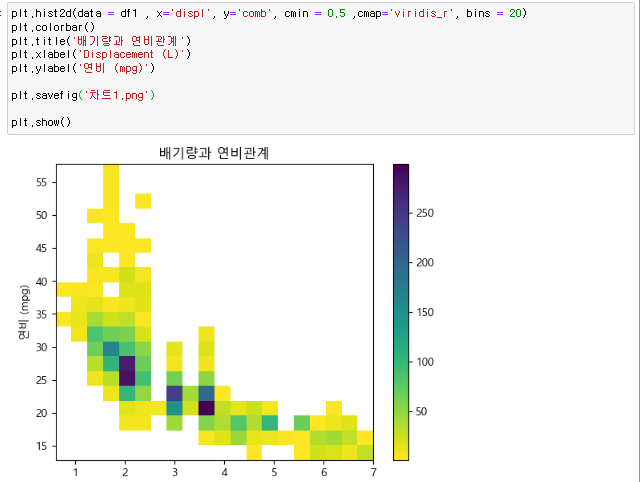
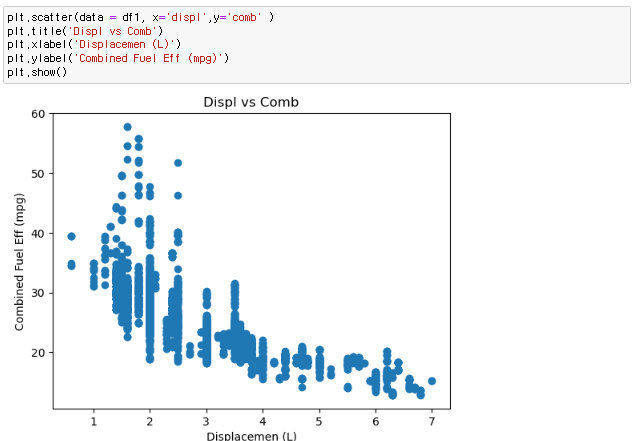
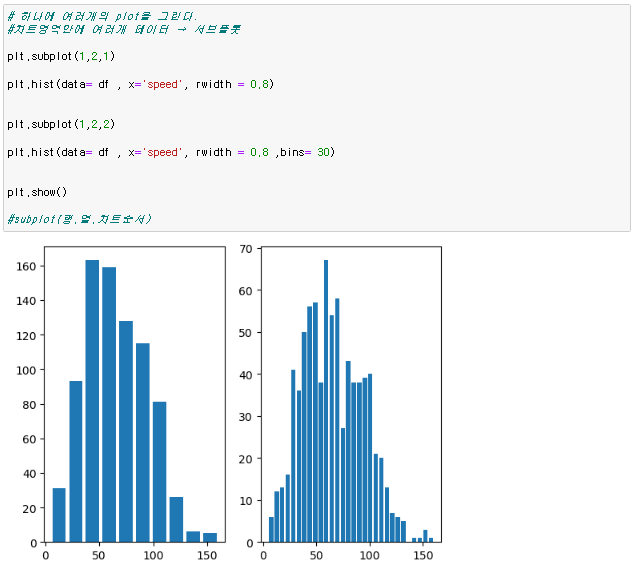
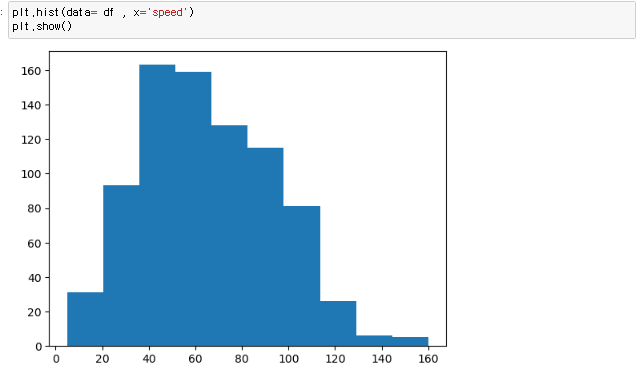
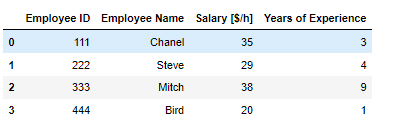
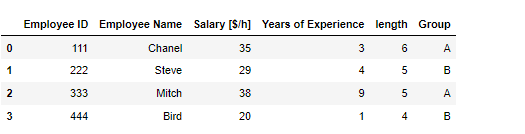피벗테이블 컬럼값을 인덱스로 만들고, 인덱스를 중복제거하여 유니크하게 만드는 방법 pd.pivot_table(데이터프레임, index = ['컬럼명'] 이러한 데이터 프레임이 있다면 여기서 Name 컬럼에 중복되는 데이터가 많다 이러한 경우 피벗테이블을 이용해 쉽게 유니크 시킬수 있음 이런식으로 중복되는 컬럼은 인덱스로 옮기며 하나로 합쳐지고 그외 숫자 데이터도 합쳐지는걸 볼수있다. 이때, 기본 디폴트는 숫자데이터의 평균 파라미터 aggfunc= np.sum 파라미터 aggfunc은 데이터 처리를 표현해줌 파라미터 values = ['컬럼명'] 원하는 데이터만 피벗테이블화 시킬수 있음 피벗테이블 함수) pd.pivot_table(데이터프레임, index = ['컬럼명']) 파라미터 aggfunc= 식 숫..