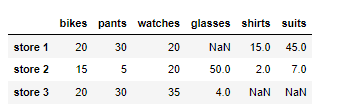
데이터 삭제하기 행과 열 삭제하기 변수.drop('인덱스' or '컬럼' , axis = 0 or 1) 1)행 삭제 저데이터 에서 store2를 삭제한다고 하면 df = df.drop('store 2' , axis=0) 2)열삭제 df.drop(['glasses'], axis = 1) 당연히 복수 삭제도 가능하다 인덱스나 칼럼명 바꾸기 변수.rename( index or columns = { '기존이름' : '바꿀이름'} ) 인덱스명 바꾸기 먼저 바꿀 인덱스명의 칼럼을 만든후 set을 통해 인덱스에 inplace (위치 시키기) 두가지의 방법이 있음 df['name'] = ['A','B','C'] 으로 새로운 컬럼을 만들고 df = df.set_index('name') df.set_index('name'..