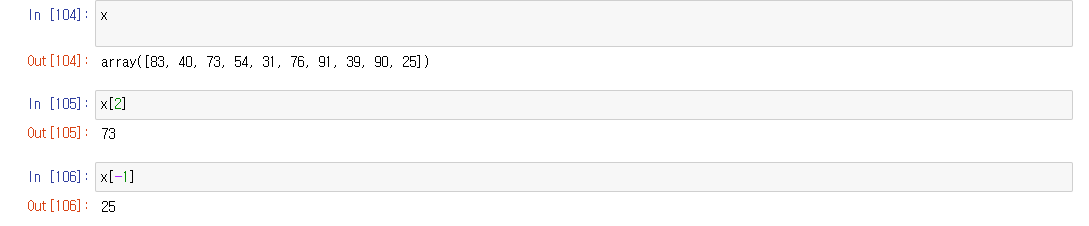
액세스한 데이터로 데이터값 변경 액세스한 값을 그대로 바꿔줄 값만 넣어 주면 쉽게 데이터 변경이 가능하다 1) 특정 위치값 추가 df['watches'] = 20 loc로 표현하면 df.loc['store 2' , 'watches'] = 20 둘다 같은 위치 값을 나타내고 있음 2)새로운 컬럼 추가 추가하고 싶은 칼럼을 액세스 하듯이 불러오면 추가가 가능하다 변수['추가할컬럼'] = [데이터] df['suits'] = df['pants'] + df['shirts'] 이런식으로 다른데이터를 이용해서 추가도 가능 새로운 행주가 새로운 딕셔너리를 만들고 기존 데이터프레임이 들어있는 변수에 append로 추가 하기 new_item = [{'bikes' : 20, 'pants':30, 'watches':35, '..