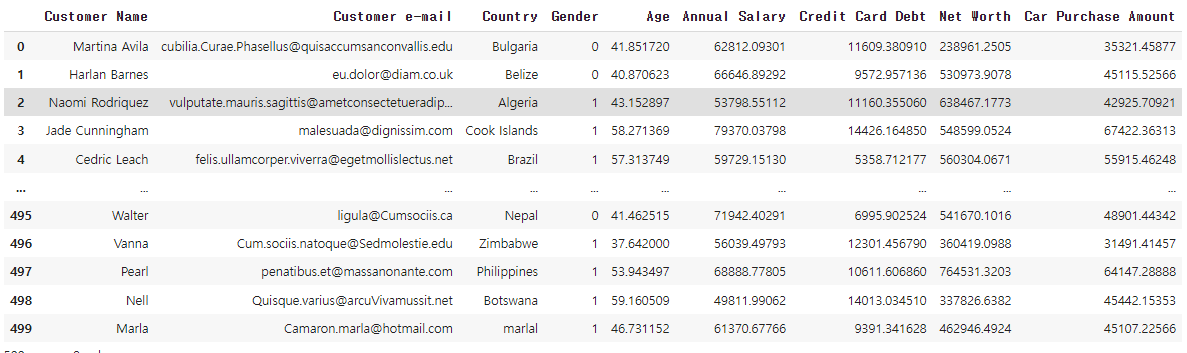
학습시 에포크차이에 따른 loss율 변화를 보는 방법 모델 학습시 이 딥러닝 중인 모델을 변수에 저장후 모델링변수.history 딕셔너리 형태로 저장이됨 = 고로 key값이 존재 한다는 의미 epoch_history.history.keys() plt.plot( epoch_history.history['loss'] ) plt.xlabel('# epochs') plt.ylabel('Loss') plt.show() 에포크 갯수에 따라 loss율의 변화를 관측 가능