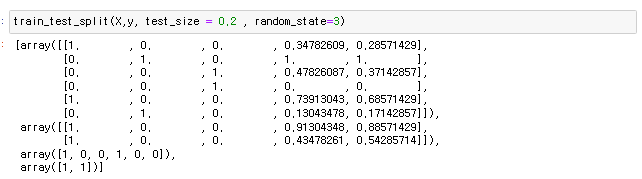
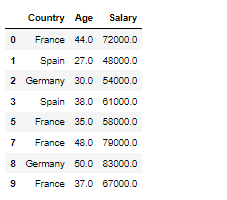
어떠한 결과를 도출해내기 위한 머신러닝을 위해 도출해내려는 값y 학습시킬 데이터를 x로 표현하는데 머신러닝을 돌렸을때 학습용만 데이터가 있다면 나중에 결과값이 정확하지 않는경우가 있음 그래서 테스트용과 트레이닝용으로 값을 나눠준다 from sklearn.model_selection import train_test_split 머신러닝을 위해 준비한 데이터는 x값이든 y값이든 트레이닝용 데이터와 테스트용 데이터 준비 train_test_split(X,y, test_size = 0.n , random_state=n) 테스트 사이즈는 0.n => 준비된 데이터의 n% 랜덤 스테이트 n은 random으로 돌릴값 sedd라고 생각 각각 순서대로 첫번째 array는 x데이터 학습 두번째는 x데이터 테스트용 3번째는 ..