
unsupervised는 결과값을 정하는 supervised 머신러닝과 다르게 데이터를 군집(클러스팅)화 하여
자동으로 묶어주는 머신러닝을 의미한다
k-means 알고리즘이란
데이터를 k개의 묶음을 정해 그거리의 평균을 내는 알고리즘을 뜻한다.
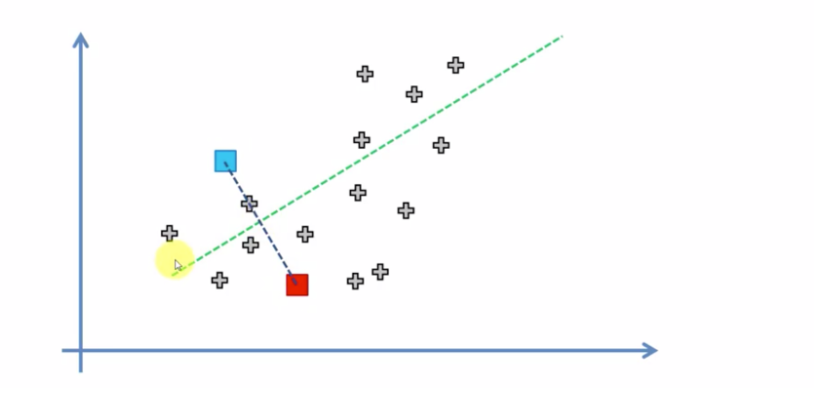
아직 군집이 정해지지 않은 데이터 무리들 사이에 임의점 점(좌표)를 찍고 그 좌표를 중심으로선을 나눠 집단을 형성

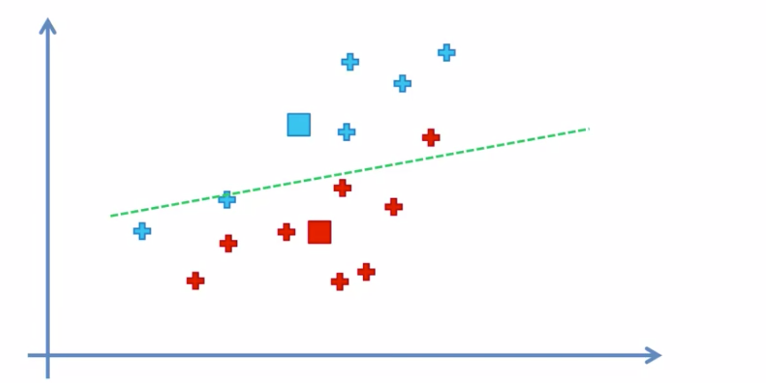
그리고 또다른 좌표를 찍고 다시 선을 그어 데이터가 나눠보면서 계속해서 이과정을 반복을한다.
이과정을 반복하다가 더이상 데이터의 변동이 일어나지 않을때 최적의 클러스팅을 찾은것

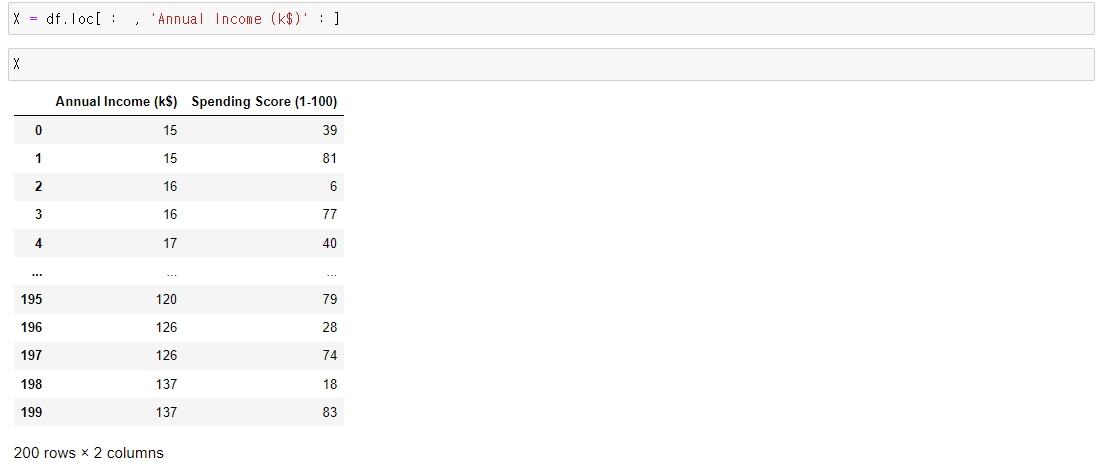
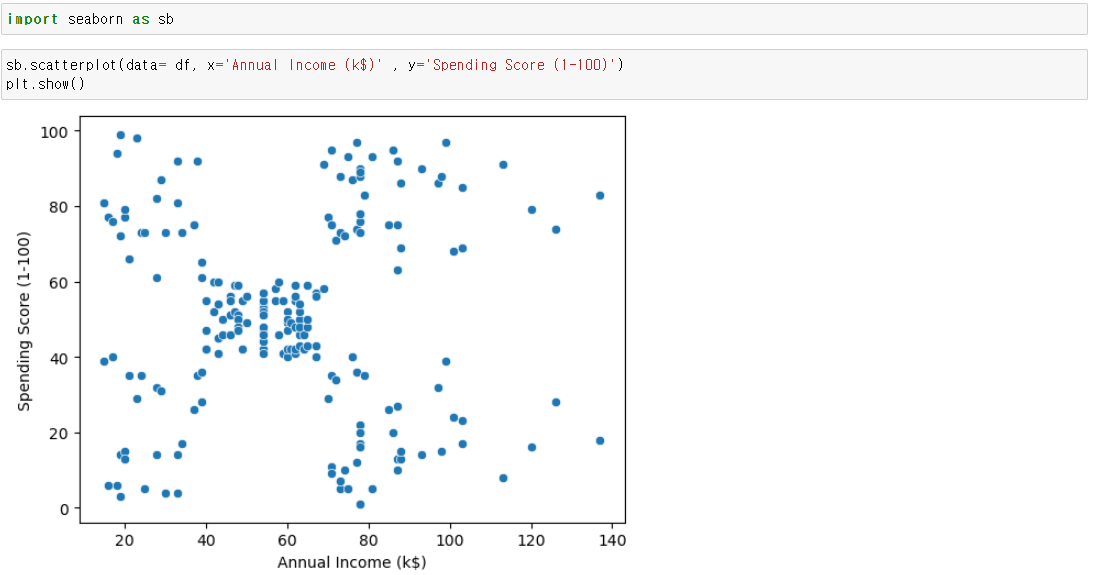
데이터는 수입별 구매점수를 의미
이데이터를 통해 여러 소비군집을 나누기
트레이닝 기본
1. nan확인
2.x와y분리
언수퍼 바이즈드 러닝은 결과값이 없기때문에 x데이터는 존재하지만 y데이터는 존재하지 않는다
3.문자열이 있다면 숫자로 바궈주기
4.피셔츠케일링을 통해 값 맞춰주기
5.트레이닝 / 테스트 셋으로 분리시키기
https://seonggongstory.tistory.com/66
[머신러닝0] 머신러닝의 기초(총정리)
머신러닝이란 데이터를 이용하여 데이터 특성과 패턴을 학습하여 그결과 밭으로 미지의 데이터에 대한 결과값을 예측하는것 머신러닝의 종류도 다양하며 용도나 상황에 따라 이용하는 툴도 정
seonggongstory.tistory.com
모델링
from sklearn.cluster import KMeans클러스터할 갯수를 정하기 전에 최적의 갯수를 정하기위해
wcss = []
for k in np.arange(1, n) :
kmeans = KMeans(n_clusters= k, random_state=n)
kmeans.fit(X)
wcss.append( kmeans.inertia_ )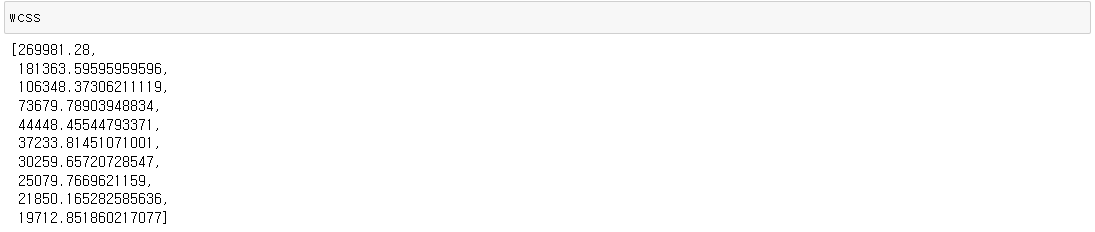

군집의 갯수가 3개와 5개 일때 wcss의 갯수가 확 차이가 난다
k의 갯수를 3개와 5개중에 선택
KMeans(n_clusters= n, random_state=n)결과 확인
이렇게 나온 군집을 결과값으로 묶어서 데이터 프레임에 그룹으로 넣어주기
스캐터로 확인하면 군집이 보임
plt.figure(figsize=[12,8])
plt.scatter(X.values[y_pred == 0, 0], X.values[y_pred == 0, 1], s = 100, c = 'red', label = 'Cluster 1')
plt.scatter(X.values[y_pred == 1, 0], X.values[y_pred == 1, 1], s = 100, c = 'blue', label = 'Cluster 2')
plt.scatter(X.values[y_pred == 2, 0], X.values[y_pred == 2, 1], s = 100, c = 'green', label = 'Cluster 3')
plt.scatter(X.values[y_pred == 3, 0], X.values[y_pred == 3, 1], s = 100, c = 'cyan', label = 'Cluster 4')
plt.scatter(X.values[y_pred == 4, 0], X.values[y_pred == 4, 1], s = 100, c = 'magenta', label = 'Cluster 5')
plt.scatter(kmeans.cluster_centers_[:, 0], kmeans.cluster_centers_[:, 1], s = 300, c = 'yellow', label = 'Centroids')
plt.title('Clusters of customers')
plt.xlabel('Annual Income (k$)')
plt.ylabel('Spending Score (1-100)')
plt.legend()
plt.show()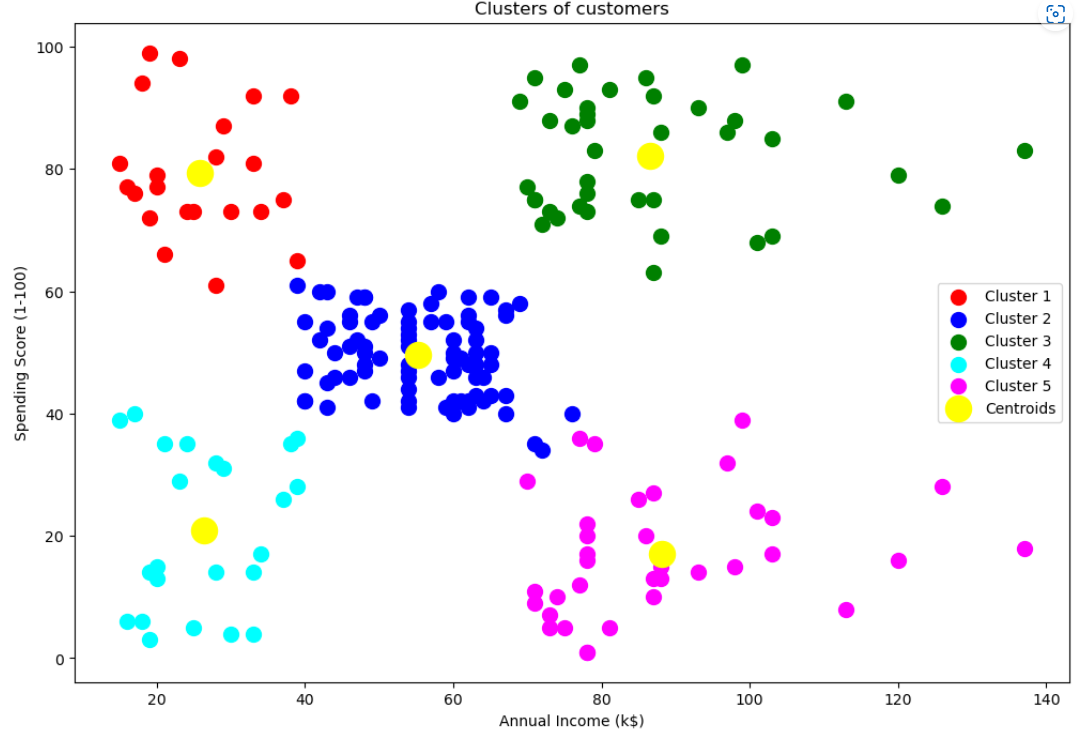
색깔을 통해 보는 군집
| k-means 데이터를 k개의 묶음을 정해 그거리의 평균을 내는 알고리즘을 뜻한다. 언수퍼 바이즈드 러닝은 결과값이 없기때문에 x데이터는 존재하지만 y데이터는 존재하지 않는다 from sklearn.cluster import KMeans 엘보우 메소드 wcss = [] for k in np.arange(1, 10+1) : kmeans = KMeans(n_clusters= k, random_state=5) kmeans.fit(X) wcss.append( kmeans.inertia_ ) plt확인 x = np.arange(1, 10+1) plt.plot( x, wcss ) plt.title('The Elbow Method') plt.xlabel('Number of Clusters') plt.ylabel('WCSS') plt.show() KMeans(n_clusters= 5, random_state=5) 스캐터 plt.figure(figsize=[12,8]) plt.scatter(X.values[y_pred == 0, 0], X.values[y_pred == 0, 1], s = 100, c = 'red', label = 'Cluster 1') plt.scatter(X.values[y_pred == 1, 0], X.values[y_pred == 1, 1], s = 100, c = 'blue', label = 'Cluster 2') plt.scatter(X.values[y_pred == 2, 0], X.values[y_pred == 2, 1], s = 100, c = 'green', label = 'Cluster 3') plt.scatter(X.values[y_pred == 3, 0], X.values[y_pred == 3, 1], s = 100, c = 'cyan', label = 'Cluster 4') plt.scatter(X.values[y_pred == 4, 0], X.values[y_pred == 4, 1], s = 100, c = 'magenta', label = 'Cluster 5') plt.scatter(kmeans.cluster_centers_[:, 0], kmeans.cluster_centers_[:, 1], s = 300, c = 'yellow', label = 'Centroids') plt.title('Clusters of customers') plt.xlabel('Annual Income (k$)') plt.ylabel('Spending Score (1-100)') plt.legend() plt.show() |
'인공지능 > 머신러닝' 카테고리의 다른 글
| [머신러닝7] 계층적 군집 알고리즘: Hierarchical Clustering / Dendogram (0) | 2022.12.05 |
|---|---|
| [머신러닝5] 의사결정나무: Decision Tree / Random Forest (0) | 2022.12.04 |
| 가장 적합한 매개변수찾기: grid search (0) | 2022.12.02 |
| [머신러닝4] Support Vector Machine (0) | 2022.12.02 |
| [머신러닝3] K-Nearest Neighbor (0) | 2022.12.02 |