서포트 벡터 머신
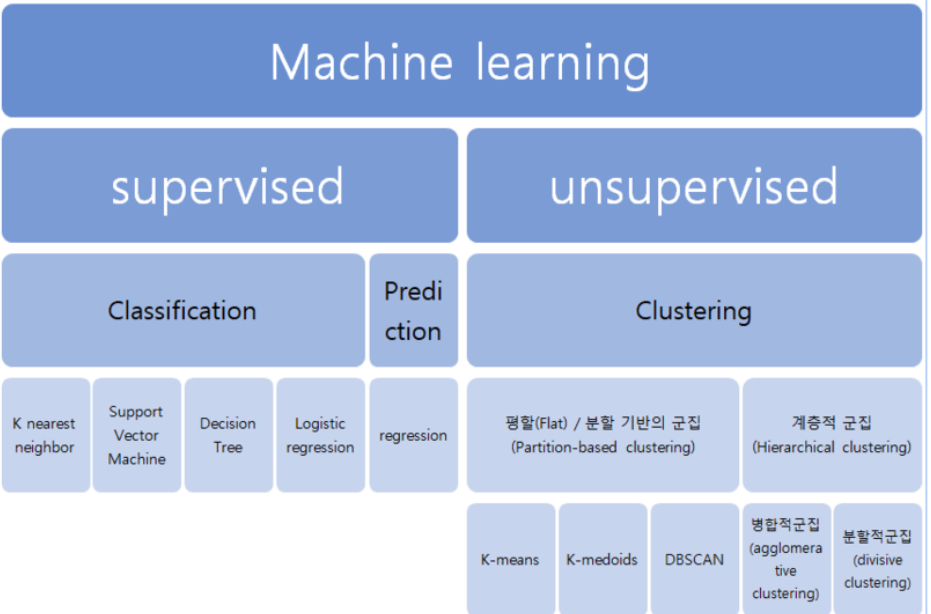
서포트 벡터머신이란
데이터를 분류하는 선중에 마진을 최대화 하는 경계면을 찾아서 나눠준다
마진이란 데이터를 분류해서 나눴을때 그 분류에서 가장 먼 데이터끼리의 사이를 의미함
가장 분류가 잘 나타나는 것들끼리 선에서 멀어지고 구분하기 힘든 데이터는 클래서파이어에 가까워짐
마진을 최대화 하여 분류하기 때문에 특이한것 까지 비슷한 부류로 묶는데에 많이 사용



동일하게 연봉과 나이 성별, 구매여부가 있는 데이터
이데이터를 KNN 머신러닝을 통해
새로운데이터가 나타났을때 어느쪽으로 분류를 할지 정하기
트레이닝 기본
1. nan확인
2.x와y분리
3.문자열이 있다면 숫자로 바궈주기
4.피셔츠케일링을 통해 값 맞춰주기
5.트레이닝 / 테스트 셋으로 분리시키기
[머신러닝0] 머신러닝의 기초(총정리) (tistory.com)
[머신러닝0] 머신러닝의 기초(총정리)
머신러닝이란 데이터를 이용하여 데이터 특성과 패턴을 학습하여 그결과 밭으로 미지의 데이터에 대한 결과값을 예측하는것 머신러닝의 종류도 다양하며 용도나 상황에 따라 이용하는 툴도 정
seonggongstory.tistory.com
모델링
from sklearn.svm import SVC
classifier = SVC( kernel = '' )
classifier.fit(X_train, y_train)SVC 의 커널 파라미터 종류에는
linear’, ‘poly’, ‘rbf’, ‘sigmoid’, ‘precomputed’ 이 있다.
기본 값은 'rbf'로 설정.


데이터 모양에따라 커널함수를 활용해서 분류를 해주면 됨
y_pred = classifier.predict(X_test)
성능평가
from sklearn.metrics import confusion_matrix, accuracy_score
confusion_matrix(y_test, y_pred)
accuracy_score(y_test , y_pred)
실제 정확도 자체는 저번 KNN으로 했을때 보다 안좋게 나왔음
이처럼 같은 자료라도 여러 인공지능으로 하나하나 해보면서 데이터에 맞는 가장높은 인공지능을 찾아내는게 중요하다

심지어 커널에 따라서도 정확도 차이가 많이나는 편이니 커널도 여러개를 해봐야 한다
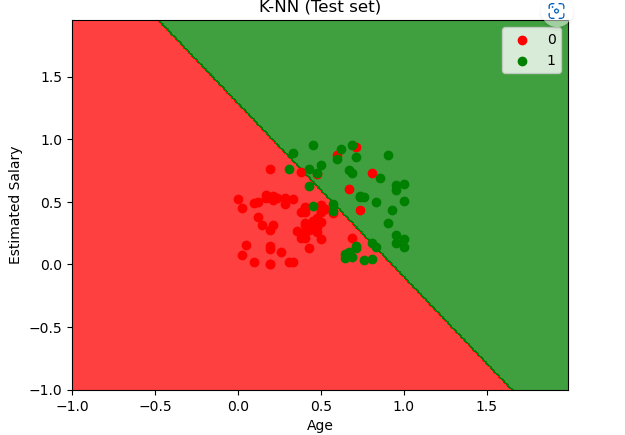
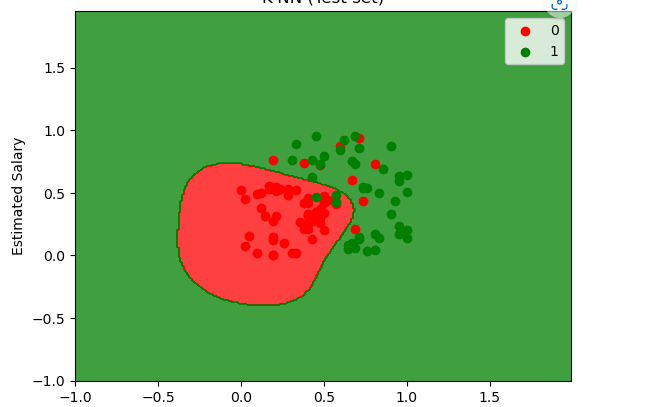
| 서포트벡터머신 마진을 최대화 하여 분류하기 때문에 특이한것 까지 비슷한 부류로 묶는데에 많이 사용 모델링 from sklearn.svm import SVC classifier = SVC( kernel = '' ) linear’, ‘poly’, ‘rbf’, ‘sigmoid’, ‘precomputed’ classifier.fit(X_train, y_train) y_pred = classifier.predict(X_test) 성능평가 from sklearn.metrics import confusion_matrix, accuracy_score confusion_matrix(y_test, y_pred) accuracy_score(y_test , y_pred) from matplotlib.colors import ListedColormap X_set, y_set = X_test, y_test X1, X2 = np.meshgrid(np.arange(start = X_set[:, 0].min() - 1, stop = X_set[:, 0].max() + 1, step = 0.01), np.arange(start = X_set[:, 1].min() - 1, stop = X_set[:, 1].max() + 1, step = 0.01)) plt.contourf(X1, X2, classifier.predict(np.array([X1.ravel(), X2.ravel()]).T).reshape(X1.shape), alpha = 0.75, cmap = ListedColormap(('red', 'green'))) plt.xlim(X1.min(), X1.max()) plt.ylim(X2.min(), X2.max()) for i, j in enumerate(np.unique(y_set)): plt.scatter(X_set[y_set == j, 0], X_set[y_set == j, 1], c = ListedColormap(('red', 'green'))(i), label = j) plt.title('K-NN (Test set)') plt.xlabel('Age') plt.ylabel('Estimated Salary') plt.legend() plt.show() |
'인공지능 > 머신러닝' 카테고리의 다른 글
| [머신러닝5] 의사결정나무: Decision Tree / Random Forest (0) | 2022.12.04 |
|---|---|
| 가장 적합한 매개변수찾기: grid search (0) | 2022.12.02 |
| [머신러닝3] K-Nearest Neighbor (0) | 2022.12.02 |
| 머신러닝중 샘플표본이 부족할때: oversampling (0) | 2022.12.02 |
| [머신러닝2] 범주형 변수예측: Logistic Regression (0) | 2022.12.02 |