df = pd.DataFrame({'Employee ID':[111, 222, 333, 444],
'Employee Name':['Chanel', 'Steve', 'Mitch', 'Bird'],
'Salary [$/h]':[35, 29, 38, 20],
'Years of Experience':[3, 4 ,9, 1]})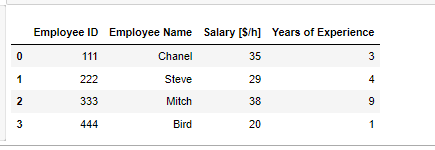
이러한 데이터에서 경력이 3년 이상인 데이터가 필요 하다면
경력 부분 컬럼인 'Years of Experience'을 엑세스 하고 3년이상인 데이터만 필터링 하면된다
df['Years of Experience'] >=3Out
0 True
1 True
2 True
3 False
Name: Years of Experience, dtype: bool
모든 데이터를 가져와야 하기 때문에
loc 함수를 이용 하고, 컬럼은 따로 쓰지 않는다
df.loc[ df['Years of Experience'] >=3 , ]
만약 여기서 연봉,사번,이름등 가저오고 싶은 데이터 컬럼이 있다면 [ , ] 오른쪽 안에 표시해주면 됨
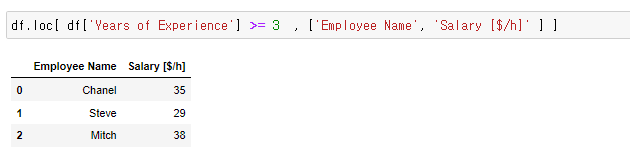
조건에 따라 계속 변하는것도 포인트
경력이 4년이상 8년 이하인 사람의 데이터를 가져오시오
4년 이상 경력
df['Years of Experience'] >=4Out
0 False
1 True
2 True
3 False
Name: Years of Experience, dtype: bool
8년이하 경력
df['Years of Experience'] >=4Out
0 False
1 True
2 True
3 False
Name: Years of Experience, dtype: bool
(df['Years of Experience'] >=4) & (df['Years of Experience'] <= 8)0 False
1 True
2 False
3 False
Name: Years of Experience, dtype: bool이런식으로 조건 수정
시급이 가장 높은 사람
찾아야 하는 조건과 기본조건이 같은 값으로 세팅 하면 됨
df['Salary [$/h]'].max()이게 최고 시급이면 시급이 최고 시급인 사람의 행을 찾으면됨
df['Salary [$/h]'] == df['Salary [$/h]'].max()
'파이썬 > 라이브러리' 카테고리의 다른 글
| 파이썬 라이브러리22 pandas 데이터프레임 정렬하기/sort/ascending (0) | 2022.11.25 |
|---|---|
| 파이썬 라이브러리21 pandas 데이터프레임 : applying 함수 (0) | 2022.11.25 |
| 파이썬 라이브러리19 pandas 데이터프레임 : 카테고리컬 데이터 /.agg /.groupby /.unique /value_counts() (0) | 2022.11.24 |
| 파이썬 라이브러리18 pandas 데이터프레임 : NaN데이터 처리 isna()/notna / dropna() / fillna() (0) | 2022.11.24 |
| 파이썬 라이브러리17 pandas 데이터프레임: drop()/rename()/인덱스 바꾸기 (0) | 2022.11.24 |